Robotics & Music
This edition of the Age of Intelligence Newsletter summarizes key developments at the intersection of robotics, music, art, and language AI from April to May 2023. It covers major advances in robotics including Boston Dynamics upgrading Spot and bipedal soccer skills developed with deep reinforcement learning. For music AI, the newsletter discusses MusicLM’s integration into Google’s AI Test Kitchen. It also highlights progress in AI art generation tools like Midjourney, Stable Diffusion, and animated drawings. Other topics include new multimodal and vision-language models like ImageBind and LLaVA, AI regulation debates involving OpenAI’s Sam Altman, and updates from tech giants like Google, Meta, and Microsoft related to large language models, AI research, and new products. Overall, this newsletter provides a snapshot of essential events and research updates in robotics, music generation, visual arts, and language AI over the past month.
Discovering Dark Matter Symbolic Models (2020)
The paper introduces a method for extracting symbolic models from deep learning architectures, incorporating inductive biases to enhance interpretability. The approach involves training a Graph Neural Network (GNN) under a supervised setting, while also promoting sparse latent representations. By applying symbolic regression to various components of the GNN, explicit physical relationships such as equations, force laws, and Hamiltonians can be identified. This enables the prediction of dark matter concentration based on the mass distribution of nearby cosmic structures, resulting in the discovery of a new analytic formula.
The authors’ technique presents an alternative means of understanding neural networks and uncovering novel physical principles through their representations. They have developed a general framework that distills symbolic representations from deep models, employing strong inductive biases. Specifically, they have focused on GNNs and encouraged sparsity in the latent representations during the supervised training process. By applying symbolic regression, they successfully extract known equations, force laws, and Hamiltonians from the neural network.
To demonstrate the effectiveness of their method, the authors applied it to a non-trivial cosmology scenario involving a detailed dark matter simulation. Remarkably, they discovered a new analytic formula that accurately predicts dark matter concentration based on nearby cosmic structures’ mass distribution. Additionally, the symbolic expressions derived from the GNN using their technique exhibited superior generalization capabilities to out-of-distribution data compared to the GNN itself.
The presented approach for distilling symbolic representations from deep learning models addresses the objective of extracting interpretable and human-understandable knowledge from complex architectures.
Perplexity.ai #tool
Perplexity.ai is a cutting-edge AI technology that harnesses the power of GPT3 and a large language model to provide users with an advanced search experience. Unlike conventional search engines, Perplexity.ai leverages natural language processing (NLP) and machine learning techniques to deliver highly accurate search results.
By integrating GPT3’s capabilities, Perplexity.ai excels at generating comprehensive and precise responses to complex inquiries. The platform goes beyond traditional search functionalities by combining search and chat features, enabling users to engage in interactive conversations while obtaining relevant information. Additionally, Perplexity.ai ensures the reliability of its search results by including footnotes that contain links to the sources of information, enabling users to verify the accuracy and authenticity of the provided data, thus mitigating the risk of misinformation.
The applications of Perplexity.ai are diverse and encompass various fields. It can efficiently handle frequently asked questions, summarize lengthy texts, and even forecast weather conditions, among other tasks. Leveraging the capabilities of the GPT model, Perplexity.ai possesses the ability to comprehend and respond to queries in a conversational manner, enhancing the user experience and facilitating more interactive interactions. Whether it’s for research, problem-solving, or general information retrieval, Perplexity.ai offers a powerful tool for users to delve into the vast realm of knowledge with unparalleled accuracy and conversational flexibility.
05/25 Aria: AI Browser by Opera
Aria is an AI-powered browser that can help you with tasks like finding information, generating text, and answering questions. It uses generative AI, specifically OpenAI’s GPT technology, to provide users with real-time information and insights. Aria can also be used to generate text or code, or to answer product queries.
Aria is available on desktop and Android devices, and it’s free to use. To use Aria, you need to download the Opera browser and enable the Aria feature. Once you’ve enabled Aria, you can access it from the sidebar of the Opera browser.
Aria is constantly being updated and improved. Opera is working to integrate additional features and search services into Aria, making it even more powerful and useful. For example, Opera is planning to integrate Aria with its ChatGPT service, which will allow users to have natural conversations with Aria.
ref: https://blogs.opera.com/desktop/2023/05/opera-unveils-integrated-browser-ai-aria/
05/25 AI Robots race begins
Boston Dynamics has recently upgraded its Spot robot dog with new software and hardware features that improve its performance in industrial settings. These new features include:
The ability to detect moving objects and navigate wet floors safely. Spot can now use its built-in cameras and sensors to detect moving objects, such as people or forklifts. This helps Spot avoid collisions and respond to emergencies. Spot can also now navigate wet floors safely by adapting to slippery environments and recovering from slips. This makes Spot a more reliable and versatile robot for industrial applications.
The ability to perform multiple inspection types simultaneously. Spot can now perform multiple inspection types simultaneously, such as thermal, gauge reading, and acoustic imaging. This allows Spot to identify and address issues early on, which can help improve safety and productivity.
The ability to communicate with humans using safety lights, a buzzer, and a speaker. Spot can now communicate with humans using safety lights, a buzzer, and a speaker. This helps humans to better understand Spot’s actions and intentions, which can improve collaboration and safety- ref: https://www.zdnet.com/article/boston-dynamics-robot-dog-learns-new-tricks-to-become-a-better-coworker/
05/24 Google Ads AI
Google Marketing Live 2023 recently unveiled exciting new generative AI capabilities for Google Ads in a blog post. These advancements position AI as an invaluable tool in the marketing arsenal, empowering marketers to make informed decisions, solve problems, and unleash their creativity. The utilization of AI in Google Ads now extends to various functionalities:
- Creation and editing of Search ads have been enhanced to deliver a more natural-language conversational experience. This improvement includes automatically generated assets that adapt to the specific context of a search query.
- Performance Max campaigns can now be scaled and customized using generative AI, which generates text and images for ads based on your website content and existing ads. This enables advertisers to effortlessly create tailored ads that resonate with their target audience.
- Search Generative Experience (SGE) enables the integration of AI-powered ads alongside organic search results. By leveraging SGE, marketers can create relevant, high-quality ads that are customized to every stage of the user’s search journey.
Google remains committed to maintaining transparency, privacy, and user trust. They continuously test new signals and products to help advertisers connect with relevant customers and accurately measure their results. For further information on these developments and other commerce-related updates, the Google Ads Help Center provides comprehensive details. Additionally, the keynote and digital post-show offer a deeper dive into the latest news.
Google Marketing Live initially launched in 2013 during the rise of mobile advertising. Today, AI stands as a transformative force within the industry and forms the foundation of Google Ads. Over the years, Google Ads has successfully employed AI to assist advertisers in optimizing their time and return on investment. With the introduction of new generative AI advancements, AI now takes center stage, serving as an indispensable tool within the marketing toolkit. The natural-language conversational experience within Google Ads simplifies campaign creation, combining the advertiser’s expertise with Google AI. By incorporating a preferred landing page from their website, advertisers can leverage Google AI’s ability to summarize the page and generate relevant and effective keywords, headlines, descriptions, images, and other assets for the campaign. These suggestions can be reviewed and easily edited before deployment. The automatic creation of assets (ACA) for Search ads, which employ content from landing pages and existing ads to generate headlines and descriptions, was introduced last year. With the integration of generative AI, ACA is set to be even more impactful, effectively creating and adapting Search ads based on the specific query context.
ref: https://blog.google/products/ads-commerce/ai-powered-ads-google-marketing-live/
05/23 Windows Copilot
Windows Copilot: Windows Copilot is an AI-powered assistance system that can help users with a variety of tasks, such as typing, editing, and navigating. It works by using Bing Chat to communicate with users and understand their needs. Windows Copilot is still in preview, but it has the potential to be a powerful tool for productivity.
Hybrid AI loop: The Hybrid AI loop is a new development pattern that allows developers to build AI-powered applications that run on both Azure and client devices. This makes it possible to build applications that take advantage of the power of Azure’s AI services while also being responsive and efficient on client devices.
Dev Home: Dev Home is a new centralized hub for developers on Windows. It provides developers with a variety of tools and resources to help them be more productive, such as WinGet configuration, Dev Drive, and a customizable dashboard. Dev Home is still in preview, but it has the potential to be a valuable resource for developers.- ref: https://blogs.windows.com/windowsdeveloper/2023/05/23/bringing-the-power-of-ai-to-windows-11-unlocking-a-new-era-of-productivity-for-customers-and-developers-with-windows-copilot-and-dev-home/
05/22 Aurora GenAI 1 Trillion Param
Intel has introduced Aurora GenAI, a new generative AI model for science with impressive capabilities.
Aurora GenAI has 1 trillion parameters, five times more than its predecessor, ChatGPT, and surpasses the free and public versions of ChatGPT.
Aurora GenAI will be trained on various scientific data and texts, including general text, code, scientific texts, and structured scientific data from multiple fields. It will find applications in molecule and material design, knowledge synthesis, proposing experiments, and identifying biological processes related to diseases.
05/22 Meta 1,000 languages
Meta has made a significant breakthrough by developing AI models capable of recognizing and generating speech in over 1,000 languages, a remarkable tenfold increase compared to current capabilities. The company has decided to release these models as open source via GitHub, allowing developers to leverage them in building innovative speech applications for various languages. This move is expected to be particularly beneficial for languages at risk of extinction, as it facilitates the creation of tools that can preserve and revitalize linguistic diversity.
The foundation of these models lies in an existing AI model developed by Meta in 2020, which possesses the ability to learn speech patterns from audio data without the need for extensive labeling. In order to enhance its performance, Meta’s researchers trained the model using two new datasets. The first dataset consisted of audio recordings of the New Testament Bible and corresponding text in 1,107 languages, sourced from the internet. The second dataset included unlabeled New Testament audio recordings in 3,809 languages. The team refined the audio and text data and employed algorithms to align the audio recordings with the corresponding text, training a second algorithm on the aligned data. This process facilitated the model’s proficiency in learning new languages, even in the absence of accompanying text.
According to Meta’s researchers, the AI models developed can converse in over 1,000 languages and recognize more than 4,000 languages. Comparisons with competing models, including OpenAI Whisper, have revealed that Meta’s models exhibit significantly lower error rates, despite covering a far greater number of languages. However, it is important to note that the models are not without their limitations. They may occasionally mistranscribe certain words or phrases, leading to inaccuracies or potentially offensive labels. Additionally, the researchers have acknowledged that their speech recognition models may contain a slightly higher proportion of biased words compared to other models, albeit only by 0.7%. The utilization of religious texts to train AI models can be a subject of controversy, and this aspect should be taken into consideration.
Overall, Meta’s achievement in developing AI models with extensive language capabilities has the potential to revolutionize communication and accessibility across a vast array of languages. The availability of these open source models opens up avenues for developers to create inclusive and language-diverse applications that can cater to a broader range of users worldwide.
05/21 AirChat
AirChat is an innovative social media platform introduced by Naval Ravikant, an Indian-American entrepreneur and investor. The platform utilizes AI technology to offer users a unique means of connecting with others. Notably, AirChat stands out with its push-to-talk layout, enabling users to engage in video conversations or audio chats similar to those found on Clubhouse. This real-time and asynchronous functionality caters to individuals who may be too busy to arrange synchronous interviews or allocate specific time slots for interviews. Additionally, AirChat distinguishes itself by allowing podcasts to run indefinitely, granting the flexibility for Aircasts to extend over extended periods, even spanning years.
Social media isn’t social - it’s performative.
— Naval (@naval) May 21, 2023
Where’s the chitchat, the banter, the easy laughter?
We made something new.
Push-to-talk, whenever you want.
With perfect transcripts and AI art.
A dinner party in your pocket.
Follow @getairchat
Never feel alone again. pic.twitter.com/V9urTOVf4u
05/19 CoDi: Composable Diffusion
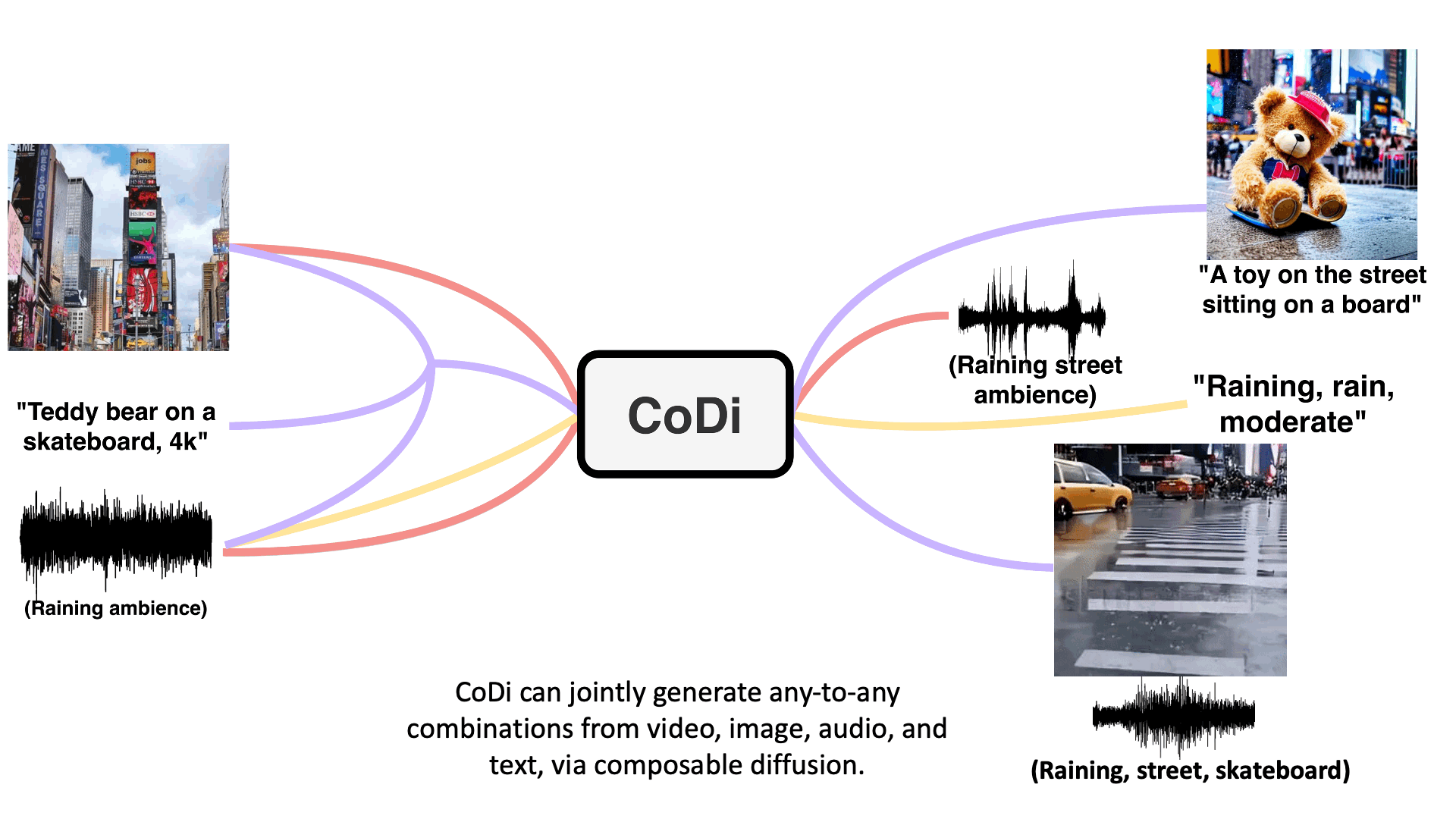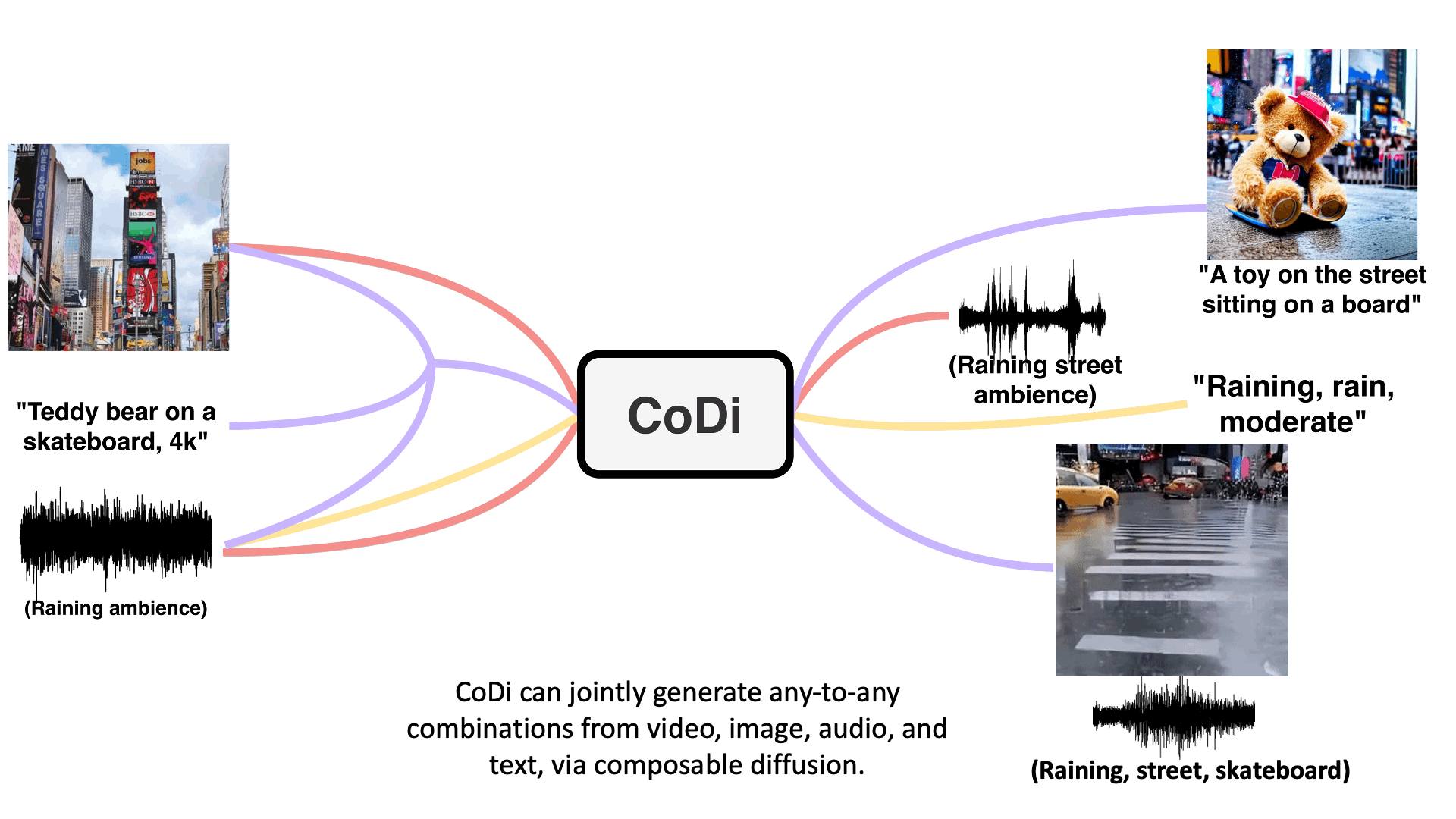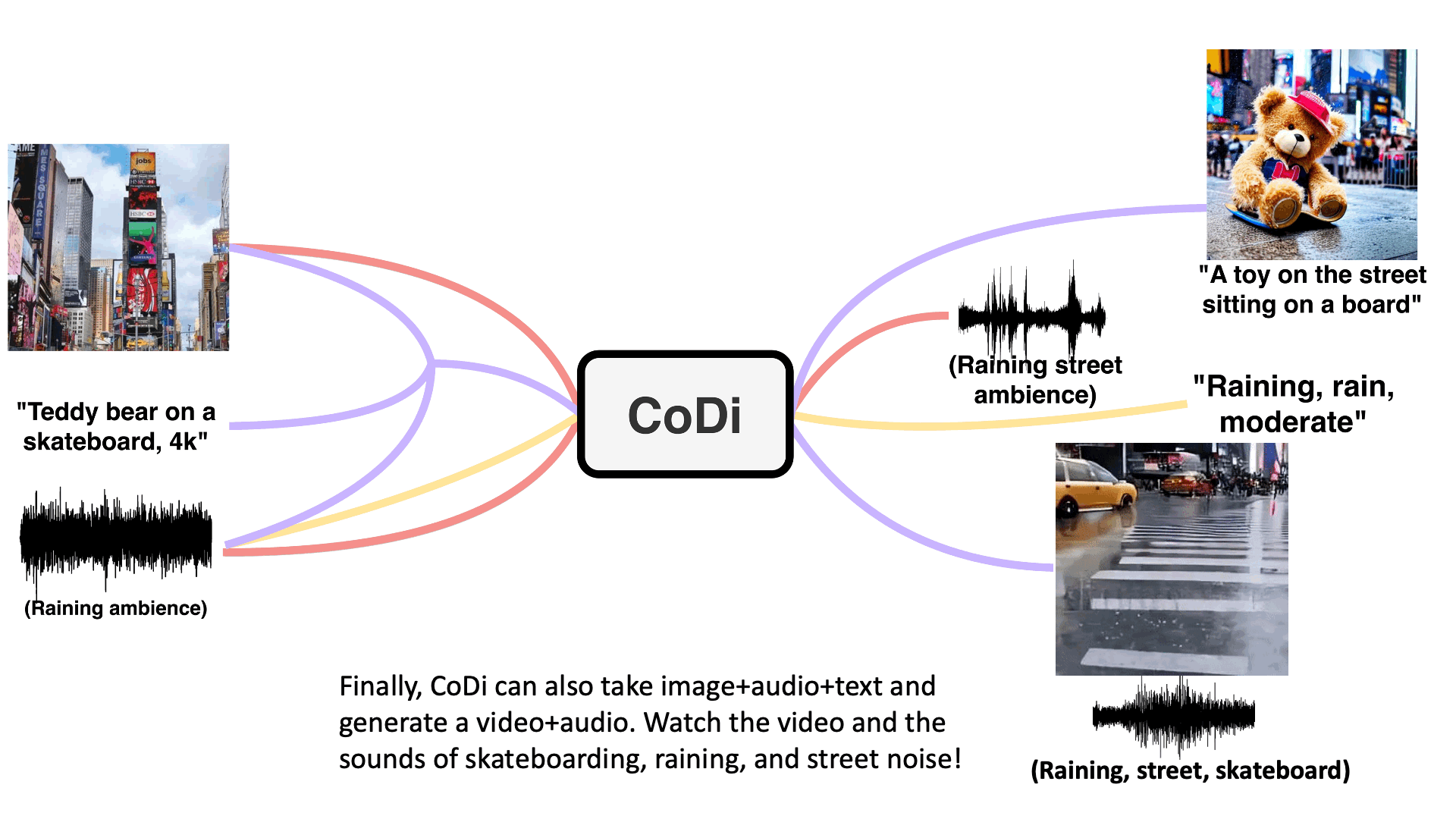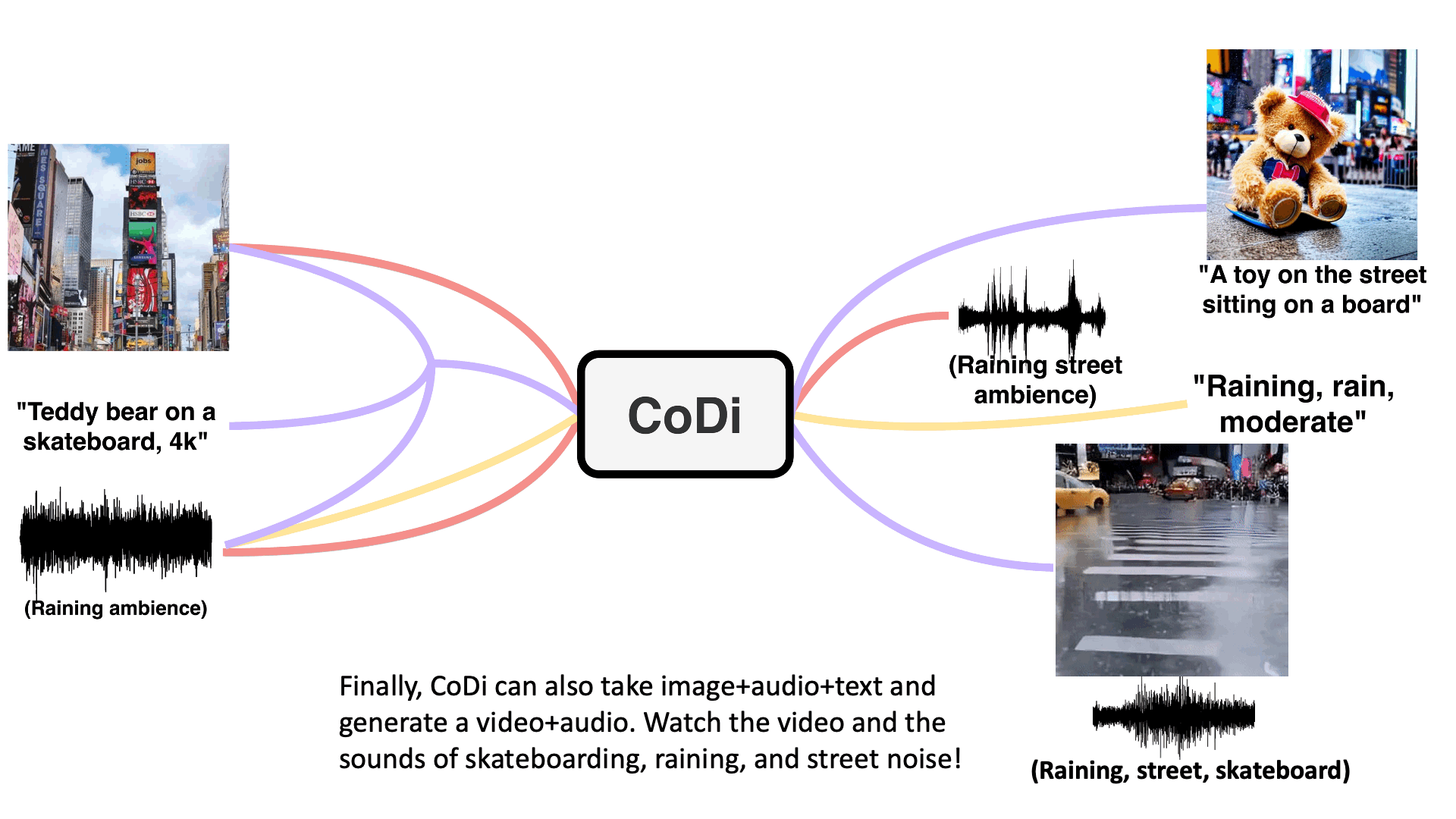
Composable Diffusion (CoDi) is an innovative generative model that introduces a groundbreaking approach to generating various combinations of output modalities from a wide range of input modalities. Unlike traditional models that are limited to specific subsets of modalities such as text or images, CoDi has the ability to generate multiple modalities simultaneously and is not constrained by any particular modality type. The key to CoDi’s success lies in its utilization of a shared multimodal space, achieved through aligning modalities in both the input and output domains. By establishing this alignment, CoDi can effectively generate diverse combinations of modalities, including language, image, video, or audio.
What sets CoDi apart is its composable generation strategy, which involves bridging alignment in the diffusion process. This strategy allows for the synchronized generation of intertwined modalities, enabling the generation of complex outputs such as temporally aligned videos with accompanying audio. CoDi’s composable approach offers a high degree of customization and flexibility, resulting in strong joint-modality generation quality.
Furthermore, CoDi showcases its superiority by outperforming or matching the state-of-the-art models dedicated to single-modality synthesis. Even without the availability of comprehensive training datasets covering all possible combinations of modalities, CoDi proves capable of generating high-quality outputs across a wide array of modalities. Its ability to generate multiple modalities in parallel, unrestricted by input limitations, makes CoDi an exceptional and versatile generative model.
05/19 Mind-Video

“Mind-Video is a novel method that leverages continuous fMRI data to reconstruct high-quality videos from brain activities. This innovative approach incorporates several key techniques, including masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and an augmented Stable Diffusion model. By utilizing these methods, Mind-Video effectively learns spatiotemporal information directly from the brain.
One notable advantage of Mind-Video is its ability to handle videos with any frame rate. The reconstructed videos exhibit impressive performance, surpassing the previous state-of-the-art by a significant margin. In semantic classification tasks, Mind-Video achieves an average accuracy of 85%, indicating its robustness in capturing meaningful content from brain signals. Additionally, it achieves a structural similarity index (SSIM) of 0.19, further demonstrating its superiority in preserving visual quality.
Moreover, the proposed Mind-Video approach is designed to be biologically plausible and interpretable, aligning with established physiological processes. This feature enhances the model’s credibility and allows researchers to gain valuable insights into the functioning of the cerebral cortex.
The research paper titled ‘Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity’ introduces MinD-Video as the key framework. MinD-Video progressively learns spatiotemporal information from continuous fMRI data through masked brain modeling, multimodal contrastive learning, and spatiotemporal attention. Additionally, it incorporates co-training with an augmented Stable Diffusion model, which includes network temporal inflation. The authors demonstrate that MinD-Video, guided by adversarial techniques, can reconstruct high-quality videos with arbitrary frame rates.
The reconstructed videos generated by MinD-Video were extensively evaluated using various metrics at both semantic and pixel levels. The impressive results obtained, such as the 85% accuracy in semantic classification tasks and the 0.19 SSIM score, highlight the effectiveness of the proposed framework. Notably, MinD-Video outperforms the previous state-of-the-art by an impressive margin of 45%.
Overall, Mind-Video and its implementation through MinD-Video present a significant advancement in video reconstruction from brain activity. The method’s ability to extract spatiotemporal information, achieve high accuracy, and maintain biological plausibility holds great promise for further understanding the intricacies of the human brain and its relationship with visual perception.”
05/19 DragGAN

DragGAN is an innovative project that introduces a novel method for controlling generative adversarial networks (GANs) through interactive point-based manipulation. Its purpose is to enable users to manipulate various aspects of GAN-generated images, including pose, shape, expression, and layout, with a high degree of flexibility, precision, and generality. The project consists of two key components. First, a feature-based motion supervision technique is employed to guide the movement of handle points towards the desired target positions. Second, a new point tracking approach utilizes the discriminative features of the GAN to continually locate the positions of the handle points accurately.
05/18 Blockade Labs: Sketch-to-Skybox Announcement
05/18 LIMA: Less Is More
LIMA, a 65B parameter LLaMa language model, has undergone two training stages: unsupervised pretraining from raw text and large-scale instruction tuning on 1,000 prompts and responses. Unlike some models, it does not utilize reinforcement learning or human preference modeling. Despite this, LIMA showcases impressive performance by learning specific response formats and demonstrating the ability to generalize to unseen tasks. In fact, LIMA surpasses or matches the performance of GPT-4, Bard, and DaVinci003 in human evaluations.
These findings suggest that the majority of knowledge in large language models is acquired during pretraining, with minimal instruction tuning data required to generate high-quality outputs. LIMA’s success stems from being fine-tuned with a supervised loss on a limited set of carefully curated prompts and responses. The model not only learns to adhere to specific response formats but also exhibits good generalization to tasks it hasn’t encountered during training.
In a controlled human study, LIMA’s responses are either equivalent to or preferred over GPT-4 in 43% of cases. This percentage increases to 58% when compared to Bard and 65% against DaVinci003, which was trained using human feedback. These results strongly support the notion that large language models acquire most of their knowledge during pretraining and only require a small amount of instruction tuning to generate high-quality output.
However, it’s important to acknowledge that LIMA, like any model, has its limitations. It may struggle with tasks that necessitate complex reasoning or knowledge beyond its training data. Furthermore, if trained on biased or inappropriate data, the model may produce biased or inappropriate responses. These considerations highlight the need for ongoing research and careful monitoring when deploying language models like LIMA.
05/17 Senate Hearing on AI Safety: We should also look at hacking culture.
OpenAI’s Chief Executive, Sam Altman, has been actively involved in advocating for the regulation of artificial intelligence (AI) through extensive engagement with lawmakers and global leaders. Altman has taken the initiative to meet with more than 100 U.S. lawmakers, including Vice President Kamala Harris and cabinet members at the White House, to discuss the need for AI regulation and to showcase ChatGPT, an AI chatbot developed by OpenAI.
During these meetings, Altman has put forward various proposals aimed at addressing the challenges associated with AI. One notable suggestion is the establishment of an independent regulatory agency dedicated to overseeing AI technologies. This agency would be responsible for setting licensing requirements and safety standards to ensure responsible and ethical AI deployment. Altman has emphasized the importance of proactively addressing the risks associated with AI, highlighting the potential dangers if left unchecked.
Altman’s efforts have garnered mixed responses from lawmakers. His candid approach and willingness to engage have impressed some, as he actively participates in congressional hearings and maintains open lines of communication with elected representatives. Altman’s proactive approach has positioned him as a key influencer in shaping the AI regulation debate. By engaging with lawmakers early on, he aims to educate them about the complexities of AI and dispel fears surrounding the technology.
However, Altman has also faced skepticism and criticism from those who question his motives and the extent of his influence. Some critics view his involvement in AI regulation as an attempt to consolidate OpenAI’s power or shape regulations to favor the company’s interests. Nevertheless, Altman’s charm offensive and genuine efforts to educate and collaborate with lawmakers have provided him with a significant platform from which to influence AI governance.
In summary, OpenAI’s CEO, Sam Altman, has actively engaged with lawmakers and global leaders to advocate for AI regulation. His proposals for an independent regulatory agency, licensing requirements, and safety standards have garnered both support and skepticism. Altman’s approach has allowed him to shape the AI regulation debate and establish himself as a prominent figure in Washington, aiming to ensure responsible and safe development and deployment of AI technologies.
From my perspective, the comparison between AI regulation and the perception of hacking in the United States is noteworthy. It is crucial to recognize that ethical hacking exists and plays a significant role in computer science advancement. Similarly, the concept of AI being unrestricted holds merit, as it enables accelerated progress across various fields. AI has already proven its immense value, particularly in areas like physics, where the boundaries of human knowledge have been approached. Imposing excessive control over the trajectory of future advancements and progress is inherently misguided.
05/13 Edge URL to Bing
Microsoft Edge, the default browser for Windows 10, has encountered a significant privacy issue. By default, it is sending all visited pages to Bing, which raises concerns about user privacy. This issue stems from a feature called “follow content creators” introduced in Edge version 112.0.1722.34. Although this feature is intended to provide suggestions for content creators to follow within Edge, it unintentionally sends information about every visited site to Bing through the bingapis.com domain. While this behavior is not an intentional data collection practice, it still gives users a reason to consider alternative browsers like Google Chrome.
To address this privacy concern and prevent Bing from collecting browsing data, users can take the following steps:
- Open Microsoft Edge and navigate to the Privacy Settings.
- Disable the “Get notified when creators you follow post new content” option.
- Turn off the “Show suggestions to follow creators in Microsoft Edge” feature.
- Restart the Edge browser.
Following these steps will stop Bing from gathering browsing data and help preserve user privacy.
05/11 100K Context by Anthropic
Anthropic is a company that has developed a remarkable natural language processing model called Claude. This advanced model possesses the ability to read, summarize, and answer questions from lengthy texts. What sets Claude apart is its capability to handle up to 100K tokens of text, which is equivalent to approximately 75,000 words, all within a timeframe of less than a minute. This breakthrough means that businesses can now submit extensive documents comprising hundreds of pages for Claude to analyze and comprehend, engaging in conversations that may span hours or even days.
Claude offers a wide range of valuable services to businesses. It excels at digesting, summarizing, and explaining intricate documents such as financial statements or research papers. Moreover, it can analyze annual reports to identify strategic risks and opportunities for a company. Claude can also navigate legal documents to uncover risks, identify prevailing themes, and distinguish different forms of argumentation. Additionally, it is adept at processing developer documentation, efficiently extracting answers to technical questions from hundreds of pages. Another impressive feature of Claude is its ability to rapidly prototype by assimilating an entire codebase and intelligently building upon or modifying it.
The Anthropic API now provides 100K context windows, enabling businesses to access this powerful tool. With Claude’s assistance, businesses can submit large volumes of text for analysis, benefiting from its remarkable comprehension and synthesis capabilities. Claude operates as a proficient language model that retrieves vital information from documents, helping businesses streamline their operations. By dropping multiple documents or even an entire book into the prompt, businesses can pose questions to Claude that require a comprehensive understanding of knowledge across different parts of the text. In complex scenarios, Claude’s performance is expected to surpass vector search-based approaches, as it can follow instructions and provide the desired information, much like a human assistant would.
To summarize, Claude, developed by Anthropic, is an impressive language model capable of reading, analyzing, and synthesizing up to 100K tokens of text within a minute. It proves invaluable in retrieving critical information from various documents, aiding businesses in their operations. With its comprehensive understanding and ability to answer complex questions, Claude stands as a powerful tool for businesses seeking efficient knowledge extraction from extensive textual resources.
05/10 Google IO: Pretty sure Google is focusing on AI at this year’s I/O
05/10 MusicLM in Google
MusicLM is now available in AI Test Kitchen.
In their paper titled “MusicLM: Generating Music From Text,” Andrea Agostinelli et al. introduce MusicLM, a model designed to generate high-fidelity music based on text descriptions. The main goal of MusicLM is to produce music that aligns with the provided textual cues while maintaining audio quality and coherence over extended durations. By surpassing previous systems in terms of audio fidelity and adherence to textual descriptions, MusicLM proves to be a notable advancement in this domain.
One of the key features of MusicLM is its ability to be conditioned on both text and a melody. This means that the model can take in whistled or hummed melodies and transform them according to the style and characteristics described in a text caption. By incorporating both textual and melodic inputs, MusicLM offers a more versatile and expressive music generation process.
To facilitate further research in this area, the authors introduce the MusicCaps dataset. This dataset consists of 5.5k music-text pairs, where each pair includes a richly detailed text description provided by human experts. By publicly releasing this dataset, the authors aim to encourage the development of new techniques and approaches in the field of music generation from text.
Overall, MusicLM presents a novel approach to generating high-quality music based on textual descriptions. Its ability to condition on both text and melody, coupled with its superior audio fidelity and adherence to textual cues, makes it a significant contribution to the field. The accompanying MusicCaps dataset further facilitates advancements in this area, providing a valuable resource for future research endeavors.
ref: https://aitestkitchen.withgoogle.com/experiments/music-lm
05/10 Infinite Games?
Nyric is a new AI platform developed by Lovelace Studio, which claims to have the capability to generate worlds for digital communities based on text prompts, much like ChatGPT. However, the platform and its parent company, Lovelace Studio, have a vague online presence, leaving many skeptical about their authenticity and their possible connection to Web 3.0 technologies.
Despite its ambitious goals, Nyric has faced significant criticism and skepticism from various quarters, including artists, developers, and journalists. One of the primary concerns raised is the question of authenticity and originality. As an AI-powered platform, Nyric’s generated content may lack the unique touch and creativity that comes with human craftsmanship. It raises doubts about whether the worlds created by Nyric would feel truly immersive and captivating to users.
Ethics also come into play when considering Nyric’s approach. The idea of an AI generating entire worlds raises concerns about the potential exploitation of content creators and the devaluation of their work. If the generated content is used without proper accreditation or compensation, it could undermine the efforts and livelihoods of artists and designers.
Adding to the skepticism surrounding Nyric is the inconsistency in messaging from Lovelace Studio. While their website boldly promotes the platform’s use for virtual reality (VR), no such mentions are found on the company’s Twitter account. This inconsistency further fuels doubts about the transparency and credibility of the project.
In conclusion, Nyric is an AI platform that claims to generate worlds for digital communities based on text prompts. However, its authenticity, originality, and ethics have come under scrutiny from artists, developers, and journalists. The concerns surrounding Nyric’s ability to deliver truly immersive and original experiences, as well as its ethical implications for content creators, raise important questions about the platform’s viability and long-term impact.
ref: https://gamerant.com/ai-platform-3d-world-generation-unreal-text-prompt/
05/10 PaLM 2

PaLM 2, developed by Google, represents a significant advancement in the field of language models. Designed to be a versatile and powerful tool, PaLM 2 boasts an impressive range of capabilities. One of its key strengths is its multilingual proficiency, as it can comprehend, generate, and translate text across more than 100 languages. This expanded language support enables users to communicate and work with diverse linguistic contexts more effectively.
Moreover, PaLM 2 demonstrates remarkable aptitude in logic, reasoning, and coding tasks. It has been trained on a vast corpus of multilingual text, including scientific papers and web pages that encompass mathematical expressions. This extensive training has equipped PaLM 2 with an enhanced ability to comprehend complex concepts, employ common sense reasoning, and even handle mathematical equations.
In terms of programming, PaLM 2 is particularly adept. It has been pre-trained on substantial datasets of publicly available source code, enabling it to excel in popular programming languages such as Python and JavaScript. However, PaLM 2 can also generate specialized code in languages like Prolog, Fortran, and Verilog. This versatility positions PaLM 2 as a valuable tool for developers and coders, empowering them to streamline their work and explore various programming languages with ease.
Google has integrated PaLM 2 into numerous products and features, totaling over 25 new additions. Among them are Bard, coding update, Workspace, Med-PaLM 2, Sec-PaLM, and Duet AI. These products leverage PaLM 2’s capabilities to enhance user experiences, productivity, and problem-solving across different domains.
As Google continues to innovate, they are already working on Gemini, a next-generation language model. Gemini is expected to be multimodal, highly efficient, and built to enable even more future advancements. With its continuous research and development efforts, Google aims to push the boundaries of language models, further expanding their applications and impact in various fields.
ref: website, Med-PaLM, Med-PaLM 2, blog
05/09 ImageBind
ImageBind is an AI model that revolutionizes multimodal learning by seamlessly integrating information from six different modalities: text, image, video, audio, depth, and thermal. This groundbreaking model accomplishes the remarkable feat of learning a single embedding space, connecting objects and concepts across various types of data. Unlike previous approaches that required explicit supervision, ImageBind achieves this feat without any explicit guidance.
The significance of ImageBind lies in its ability to enhance artificial intelligence systems by enabling machines to analyze and comprehend multiple forms of information collectively. With ImageBind, machines can generate images from audio, recognize objects from depth data, or even create immersive media from text and images. By consolidating the understanding of different data types, ImageBind paves the way for more comprehensive and holistic AI systems.
Moreover, ImageBind is an open-source tool, making it accessible for researchers and developers to explore the realm of multimodal learning and develop innovative applications. Meta, the driving force behind ImageBind, aims to construct multimodal AI systems that can effectively learn from the vast array of data surrounding them. By bridging the gap between diverse modalities, ImageBind moves closer to achieving machine comprehension akin to human perception.
This AI model seamlessly combines information from six modalities—text, image, video, audio, depth, and thermal—without the need for explicit supervision. It establishes a shared representation space, or embedding, that unifies objects and concepts across different types of data. ImageBind empowers machines to analyze and interpret diverse forms of information simultaneously, enabling them to perform tasks like generating images from audio, identifying objects from depth data, or creating immersive media from text and images.
As an open-source tool, ImageBind facilitates the exploration of multimodal learning and the creation of new applications by researchers and developers. It represents a significant step in Meta’s quest to develop multimodal AI systems that learn from the full spectrum of available data. With ImageBind, machines can achieve a holistic understanding of data, much like humans do. By enabling machines to bind information from multiple modalities, ImageBind advances the field of AI and opens up possibilities for various novel applications.
ImageBind is an AI model that excels in integrating information from six distinct modalities: text, image, video, audio, depth, and thermal. Unlike previous approaches that required explicit supervision, ImageBind learns a shared embedding space that connects objects and concepts across different types of data. This breakthrough enables machines to analyze and process multiple forms of information together, such as generating images from audio, recognizing objects from depth data, or creating immersive media using text and images.
One notable aspect of ImageBind is its availability as an open-source tool, empowering researchers and developers to explore multimodal learning and create innovative applications. As part of Meta’s efforts to develop multimodal AI systems, ImageBind enables machines to learn from diverse data sources. By establishing connections between various modalities, ImageBind moves closer to emulating human-like holistic analysis.
The significance of ImageBind extends beyond its ability to combine information from different modalities. It outperforms previous models specialized in individual modalities, showcasing its potential to enhance AI systems’ analytical capabilities. This advancement in AI opens doors for researchers to develop new applications that leverage the synergy of modalities, such as combining 3D and IMU sensors for immersive virtual experiences or conducting comprehensive searches based on a combination of text, audio, and image inputs.
In summary, ImageBind represents a cutting-edge AI model that harmonizes information from six modalities, fostering a holistic understanding of data. Its open-source nature encourages exploration and application development, while its performance surpasses previous specialized models. ImageBind contributes to the evolution of multimodal AI systems and facilitates the development of novel applications that leverage the power of diverse data sources.
05/08 Causal Reasoning
The paper titled “Causal Reasoning and Large Language Models: Opening a New Frontier for Causality?” explores the capabilities and limitations of large language models (LLMs) in the field of causal reasoning. The authors argue that LLMs possess the potential to tackle complex causal reasoning tasks by utilizing distinct sources of knowledge and methods that complement those used by non-LLM approaches. They highlight the unique abilities of LLMs, such as generating causal graphs and extracting causal context from natural language, which were previously thought to be exclusive to human cognition.
The paper demonstrates that LLMs achieve state-of-the-art accuracy on multiple causal benchmarks, making them a valuable resource alongside existing causal methods. LLMs can serve as a proxy for human domain knowledge, reducing the human effort required in setting up a causal analysis. The findings of this research have significant implications across various domains with societal impact, including medicine, science, law, and policy.
However, the authors also acknowledge that LLMs exhibit unpredictable failure modes, necessitating techniques to interpret their robustness. Understanding and addressing these failure modes is crucial to enhance the reliability and usefulness of LLMs in causal reasoning tasks. Furthermore, the paper emphasizes the importance of integrating existing causal methods with LLMs. By leveraging established causal approaches, LLMs can formalize, validate, and communicate their reasoning, particularly in high-stakes scenarios.
In summary, the paper provides insights into the potential of LLMs in causal reasoning, highlighting their distinct capabilities and contributions to the field. It also emphasizes the need for interpreting their robustness and combining LLMs with existing causal methods to harness their full potential in practical applications across various domains.
05/08 Midjourney v5.1
Midjourney 5.1, an advanced AI art service, has recently been unveiled as a significant upgrade to its predecessor, Midjourney 5. The newly released version of Midjourney, as per the information gathered from various sources, boasts a more opinionated approach compared to its predecessor. By combining the user-friendly interface of Midjourney 4 with the superior image quality of Midjourney 5, Midjourney 5.1 offers a compelling package for art enthusiasts.
One of the notable improvements in Midjourney 5.1 lies in its enhanced coherence, which results in more seamless and coherent artistic outputs. The model excels in capturing intricate details, providing users with stunning visuals that surpass the capabilities of Midjourney 5. Furthermore, Midjourney 5.1 offers improved sharpness, contributing to the overall visual appeal of the artwork it generates.
Another striking feature of Midjourney 5.1 is its ability to create expressive faces that align with the desired mood or attitude of the subject or event being depicted. This enhancement adds a new level of realism and emotional depth to the generated art pieces, enhancing the overall experience for both the artists and viewers alike.
With these advancements, Midjourney 5.1 represents a significant step forward in the field of AI-driven art creation. Its combination of enhanced coherence, improved details, heightened sharpness, and expressive faces offers a compelling artistic tool that pushes the boundaries of what AI can achieve in the realm of visual creativity.
05/04 Bing Chat Plugin
Bing Chat, powered by GPT-4, has recently become accessible to all users without the need for a waitlist. To utilize this chatbot, individuals can simply log in to Bing or Edge using their Microsoft account. This update brings a range of new features and enhancements to Bing Chat. Notably, users can now obtain image and video results directly within the chat interface. Additionally, the integration of Bing and Edge Actions allows for seamless navigation and interaction. Another valuable addition is the introduction of persistent chat and history, enabling users to retain and refer back to previous conversations. Moreover, Bing Chat now supports plug-ins, opening up possibilities for developers to extend its functionality. In collaboration with OpenTable and WolframAlpha, Microsoft is working to enable plug-ins for restaurant bookings and data visualizations, respectively. Further information on these developments is expected to be shared at the upcoming Build conference. To learn more about the comprehensive preview of Bing Chat, interested individuals can explore the detailed preview materials.
ref: https://www.theverge.com/2023/5/4/23710071/microsoft-bing-chat-ai-public-preview-plug-in-support
05/03 Reading Visual Cortex
The article “Learnable latent embeddings for joint behavioral and neural analysis” proposes a new method called CEBRA that can jointly use behavioral and neural data to produce consistent, high-performance latent spaces 12. CEBRA can be used for both calcium and electrophysiology datasets, across sensory and motor tasks, and in simple or complex behaviors across species. It allows for single and multi-session datasets to be leveraged for hypothesis testing or can be used label-free. CEBRA can be used for the mapping of space, uncovering complex kinematic features, and rapid, high-accuracy decoding of natural movies from visual cortex.
ref: https://cebra.ai/
05/03 ShapE Generate 3D
Shap·E is an innovative conditional generative model designed for generating 3D assets. Unlike traditional methods that generate meshes or point clouds, Shap·E directly generates the parameters of implicit functions, allowing for the creation of textured meshes and neural radiance fields. The training process of Shap·E consists of two stages. In the first stage, an encoder is trained to map 3D assets into the parameters of the implicit function. Then, in the second stage, a conditional diffusion model is trained using the outputs of the encoder.
One of the remarkable features of Shap·E is its ability to generate complex and diverse 3D assets within a matter of seconds, given that it is trained on a large dataset of paired 3D and text data. Despite the higher-dimensional, multi-representation output space it models, Shap·E demonstrates faster convergence and achieves comparable or even superior sample quality compared to Point·E, which is an explicit generative model based on point clouds.
Overall, Shap·E presents a promising approach to 3D asset generation by directly generating implicit function parameters, enabling the creation of textured meshes and neural radiance fields. Its training process and capabilities make it a valuable tool for generating a wide range of intricate and varied 3D assets efficiently and effectively.
05/03 Mojo🔥 35000x faster than Python
Mojo🔥 is an innovative programming language that brings together the best of both worlds: the user-friendly nature of Python and the exceptional performance of C. Developed by a team of creators, Mojo has been designed to deliver remarkable speed, surpassing Python by up to 35,000 times in specific scenarios, particularly in tasks like training deep neural networks.
One of the standout features of Mojo is its native support for multiple hardware backends. Whether it’s CPUs, GPUs, TPUs, or custom ASICs, Mojo allows developers to harness the power of various hardware types, leveraging their individual strengths. This flexibility enables optimal performance and scalability in different computing environments.
Another notable aspect of Mojo is its high-level syntax and semantics, which closely resemble those of Python. This similarity makes it incredibly convenient for developers already proficient in Python to learn and utilize Mojo effectively. By offering a familiar programming experience, Mojo eliminates the need for a steep learning curve, enabling developers to transition seamlessly and quickly adapt to this new language.
Moreover, Mojo is a superset of Python, meaning that it builds upon the syntax and functionality of Python while introducing additional features and optimizations. This unique characteristic makes it particularly advantageous for businesses and developers who heavily rely on Python for their projects. By transitioning to Mojo, they can take advantage of its exceptional speed while preserving the existing codebase and utilizing the vast ecosystem of Python libraries and tools.
The increased speed and efficiency of Mojo present significant benefits for developers and businesses alike. By harnessing a language that can be up to 35,000 times faster than Python, projects can be completed more swiftly and with reduced computing resources. This translates into tangible time and cost savings, allowing organizations to optimize their workflows, enhance productivity, and allocate resources more efficiently.
Overall, Mojo represents a compelling option for developers seeking a performance-oriented language without sacrificing the ease of use and versatility associated with Python. With its impressive speed and compatibility with existing Python infrastructure, Mojo has the potential to revolutionize the way developers approach computationally intensive tasks, empowering them to achieve faster and more efficient results.
05/02 Writer Strike
Currently, the Writers Guild of America (WGA) is in the midst of a strike, primarily driven by concerns surrounding the use of generative AI in the creation of film and TV scripts. While the strike encompasses various issues, the WGA’s focus on AI arises from two significant reasons. Firstly, the WGA seeks to protect its intellectual property rights, aiming to prevent its members’ work from being exploited as training data for AI systems. They argue that existing scripts should not be utilized in training AI models to avoid potential intellectual property theft. Some WGA members have even described AI as “plagiarism machines,” reflecting the unease around this technology.
Secondly, the WGA wants to avoid being underpaid for rewriting AI-generated drafts. They contend that writers should not be burdened with fixing “sloppy first drafts” created by AI systems. To address these concerns, the WGA aims to impose restrictions on the use of generative AI in writing scripts for film and television. Specifically, they are advocating for a definition of “literary material” or “source material” in their contract, to ensure that first drafts generated by AI models are not considered as such.
However, the Hollywood studios have rejected the WGA’s proposals thus far. Instead, they have only offered to discuss new technologies on an annual basis. The negotiations between the WGA and the studios are ongoing, and the outcome remains uncertain. The strike highlights the challenges of integrating emerging technologies, such as generative AI, into a creative industry like entertainment, where intellectual property, artistic integrity, and fair compensation are crucial considerations.
05/01 IBM Jobs Cut
IBM, under the leadership of CEO Arvind Krishna, recently made an announcement regarding their plans to pause hiring for certain back-office positions that are likely to be replaced by artificial intelligence (AI) within the next five years. This decision would impact approximately 26,000 workers, which accounts for around 30% of the company’s non-customer-facing roles, such as those in human resources. However, it’s important to note that not all roles within these departments would be automated, as certain responsibilities like evaluating workforce composition and productivity would still require human involvement.
Currently employing around 260,000 individuals, IBM will continue to hire for software and customer-facing positions. Earlier this year, the company had already implemented a reduction of about 5,000 jobs as part of its cost-saving initiatives. IBM aims to achieve annual savings of $2 billion by the year 2024. Despite these adjustments, Krishna expressed his belief that the United States would be able to avoid a recession until late 2022. However, he now acknowledges the potential for a “shallow and short” recession by the end of the present year.
Krishna remains optimistic about IBM’s prospects, citing the company’s robust software portfolio, including the acquisition of Red Hat. He believes that this diversified offering will contribute to IBM’s ability to sustain steady growth even in the face of worsening macroeconomic concerns.
04/27 Microsoft Designer
Microsoft Designer is a powerful tool that empowers users to create captivating visuals and graphics for various purposes, whether it be for business or personal use. This versatile tool offers a wide array of features and functionalities, making it suitable for designing a range of items such as signs, invitations, logos, social media posts, website banners, and more.
One of the key strengths of Microsoft Designer lies in its extensive collection of templates and design elements. These resources provide users with a solid foundation to build upon, enabling them to produce professional-grade designs with ease. Whether you’re a seasoned designer or just starting out, the intuitive interface and comprehensive library of assets help streamline the design process and bring your creative vision to life.
What sets Microsoft Designer apart is its integration of cutting-edge generative AI technology. Since its initial launch in October 2022, the AI models powering the tool have undergone continuous improvement, resulting in enhanced capabilities and an even more refined user experience. Leveraging the power of AI, Microsoft Designer assists users in generating visually striking graphics and streamlining their creative workflows.
With the latest AI technology at its core, Microsoft Designer simplifies the creative journey by providing a seamless user experience. It enables users to quickly get started on their design projects, offering suggestions, auto-completion, and other intelligent features that augment the creative process. Moreover, Microsoft Designer helps overcome creative roadblocks by offering insights and recommendations, ensuring that users can achieve their desired outcomes efficiently and effectively.
In summary, Microsoft Designer is a robust design tool that combines an extensive template library, intuitive interface, and cutting-edge AI technology. By leveraging its features and functionalities, users can create stunning visuals for their business or personal endeavors, all while enjoying a streamlined and efficient design process.
04/26 DeepMind Bipedal Robot
'Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning'
— Smoke-away (@SmokeAwayyy) May 1, 2023
By @DeepMindpic.twitter.com/znv71BcekR
The study titled “Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning” explores the application of Deep Reinforcement Learning (Deep RL) in training a low-cost, miniature humanoid robot. The objective is to enable the robot to acquire sophisticated and safe movement skills that can be utilized in complex behavioral strategies within dynamic environments. To achieve this, the researchers employed Deep RL techniques and focused on teaching the robot how to participate in a simplified one-versus-one soccer game.
The outcome of the training was the development of a policy that demonstrated robust and dynamic movement skills, surpassing initial expectations for the robot. The trained robot exhibited various abilities such as rapid fall recovery, walking, turning, kicking, and smoothly transitioning between these actions in a stable and efficient manner. Additionally, the trained agents showed a rudimentary strategic understanding of the game, including anticipating ball movements and blocking opponent shots. Notably, these behaviors emerged from a small set of simple rewards.
The training process was conducted in simulation, and the learned policies were successfully transferred to real robots without the need for further fine-tuning. Despite the presence of significant unmodeled effects and variations across robot instances, the researchers achieved successful zero-shot transfer by incorporating high-frequency control, targeted dynamics randomization, and perturbations during training in simulation.
By leveraging Deep RL, the study demonstrated that even low-cost humanoid robots can acquire agile and dynamic movement skills while ensuring safety. The trained robots surpassed a scripted baseline, showcasing notable improvements such as 156% faster walking, 63% reduced recovery time, and 24% faster kicking. These skills were effectively combined to achieve long-term objectives.
The researchers also observed that minor hardware modifications and basic regularization during training contributed to the robots’ ability to learn effective and safe movements within dynamic environments, despite their inherent fragility. Overall, the study highlights the potential of Deep RL in synthesizing complex skills for humanoid robots, paving the way for advancements in robotic agility and adaptability across various applications.
04/20 MiniGPT-4
MiniGPT-4 is highly computationally efficient as it only trains a projection layer utilizing approximately 5 million aligned image-text pairs. This lightweight alternative to GPT-4 aims to overcome some of the limitations of traditional language models.
Despite its advanced capabilities, MiniGPT-4 still faces certain challenges. The model’s inference speed is relatively slow, even with high-end GPUs, which can lead to slower results. Additionally, since MiniGPT-4 is built upon large language models (LLMs), it inherits some of their limitations, such as unreliable reasoning ability and the tendency to generate false or non-existent knowledge.
In conclusion, MiniGPT-4 represents a promising step towards bridging the gap between vision and language models. While it demonstrates impressive vision-language capabilities and addresses some issues through dataset curation and finetuning, it still has room for improvement in terms of inference speed and mitigating inherited limitations from LLMs.
04/20 DeepMind & Google Brain
Google DeepMind, a new unit formed by the collaboration of two renowned AI teams from Google and DeepMind, aims to advance the development of capable and responsible general AI systems. Under the joint leadership of Demis Hassabis, CEO of Google DeepMind, and Jeff Dean, Chief Scientist of Google, the unit will work alongside James Manyika, CEO of Google Research, and his existing Tech & Society teams. By merging the expertise, resources, and groundbreaking contributions of both teams, which have made significant strides in AI with projects like AlphaGo, Transformers, TensorFlow, and deep reinforcement learning, the unit seeks to expedite progress in the field of AI.
In addition to technical advancements, Google DeepMind will actively tackle societal issues where AI can make a positive impact, including health, climate, and sustainability. The unit recognizes the potential of AI to address these challenges and is committed to leveraging its capabilities for the betterment of society.
The blog post conveying this news exudes enthusiasm and optimism for the future of AI. The author highlights the potential of Google DeepMind to unlock human potential, revolutionize industries, and empower organizations to extract valuable insights from their data, improve customer relationships, boost sales, and gain a competitive edge in various domains.
Furthermore, the accomplishments of Google DeepMind are showcased, illustrating its practical applications. The system has demonstrated the ability to conserve energy, detect eye diseases, accelerate scientific research, and enhance Google’s products on a global scale. Notably, it has even contributed to reducing Google’s electricity expenses through improved energy efficiency.
Overall, the formation of Google DeepMind signifies a significant step towards advancing AI capabilities, fostering responsible AI development, and addressing critical societal challenges, while harboring optimism for the future potential of AI.
04/18 GPT detectors are biased against non-native English writers
The paper evaluates the performance of GPT detectors, which are widely used to identify AI-generated content, on writing samples from native and non-native English writers. The paper finds that the detectors misclassify non-native English samples as AI-generated, while native samples are correctly identified. The paper also shows that prompting strategies can bypass the detectors and suggest that they may penalize writers with constrained linguistic expressions. The paper calls for a broader conversation about the ethical implications of using ChatGPT content detectors and warns against their use in evaluative or educational settings.
04/18 ChatDoctor
Fine-tuning large linguistic dialogue models using data derived from doctor-patient conversations has proven to be highly beneficial in enhancing the models’ understanding of patients’ needs. By incorporating real-time and authoritative information from a knowledge brain, which draws from sources like Wikipedia and medical-domain databases, these models can provide reliable answers to patients’ questions. The fine-tuned model specifically designed for doctor-patient dialogues surpasses the performance of ChatGPT in terms of precision, recall, and F1 scores. This improvement can be attributed to the dataset used for fine-tuning, which encompasses a wealth of medical expertise tailored for the application of linguistic dialogue models in the medical field. To further enhance its capabilities, an autonomous ChatDoctor model has been proposed, integrating the ability to analyze and incorporate novel expertise in real-time through the utilization of an external knowledge brain. This approach ensures that the model remains up to date with the latest developments in the medical field, providing accurate and reliable information to patients during their interactions.
04/17 LLaVA: Visual Instruction Tuning
The paper introduces LLaVA, an end-to-end trained large multimodal model designed to bridge the gap between vision and language understanding. LLaVA connects a vision encoder with a language model (LLM) and demonstrates impressive capabilities in multimodal chat. The model is instruction-tuned on the language-only GPT-4, which allows it to generate multimodal language-image instruction-following data. In evaluations, LLaVA achieves an 85.1% relative score compared to GPT-4 on a synthetic multimodal instruction-following dataset, highlighting its superior performance. Additionally, when fine-tuned on Science QA, the combination of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. To facilitate further research, the paper makes available GPT-4 generated visual instruction tuning data, as well as the model and code base used in LLaVA. Overall, the LLaVA paper presents a comprehensive approach to multimodal understanding and contributes valuable resources to the research community.
04/15 Auto-GPT
Auto-GPT is an experimental, open-source Python application that utilizes the power of GPT-4 to operate independently. Acting as an “AI agent,” Auto-GPT has the capability to perform tasks with minimal human involvement, relying on self-prompting to generate responses. One of the key strengths of Auto-GPT lies in its versatility, as it can be employed in various ways to enhance productivity, creativity, and efficiency across multiple domains.
With Auto-GPT, the range of applications is vast. From conducting sentiment analysis to aiding in program development, it presents boundless possibilities for innovation and automation. By eliminating flawed data points and fortifying adaptability to change, Auto-GPT can help mitigate decision-making errors, resulting in more reliable and robust outcomes.
Moreover, Auto-GPT exhibits the ability to oversee the entire software development lifecycle, from inception to completion. It acts as a competent assistant, offering insights and making intelligent recommendations for process optimization, thereby enabling businesses to autonomously enhance their net worth.
The advantages of utilizing Auto-GPT are manifold. Firstly, its autonomy allows it to function independently, requiring minimal human intervention. This self-sufficiency translates into improved productivity, as it can automate tasks, freeing up valuable time and resources. Additionally, Auto-GPT streamlines workflows, increasing efficiency and reducing the likelihood of errors in decision-making processes.
Furthermore, Auto-GPT fosters an environment conducive to innovation. Its open-source nature encourages collaboration and customization, enabling users to tailor the application to their specific needs and contribute to its ongoing development. As an open-source project, Auto-GPT is freely available, making it accessible to a wide range of users and facilitating its adoption in various contexts.
In summary, Auto-GPT represents a significant advancement in leveraging the capabilities of GPT-4 for autonomous operations. Its wide array of applications, coupled with its ability to enhance productivity, streamline workflows, and promote innovation, positions it as a valuable tool for individuals and businesses alike. With its open-source nature, Auto-GPT offers a promising avenue for exploration, enabling users to tap into its potential and contribute to its evolution.
04/13 CodeWhisperer
CodeWhisperer is a machine learning-powered code generator that revolutionizes the coding experience. With its real-time code recommendations, it serves as a versatile tool capable of enhancing your coding efficiency. Acting as a supercharged auto-complete feature, it significantly reduces the time spent on typing individual lines or blocks of code. As you engage with CodeWhisperer, it dynamically generates suggestions based on your existing code and comments, providing a seamless coding experience.
One of the notable advantages of CodeWhisperer is its ability to expedite the coding process. By offering real-time suggestions as you type, it empowers you to write code swiftly and effortlessly. This feature not only saves time but also streamlines the development workflow, allowing you to focus on writing high-quality code rather than being bogged down by repetitive tasks.
CodeWhisperer also contributes to improved productivity. With its assistance, you can allocate more attention to developing robust solutions rather than getting caught up in mundane coding details. By automating the generation of code snippets and providing intelligent suggestions, it frees up valuable mental space, enabling you to tackle complex programming challenges more effectively.
Furthermore, CodeWhisperer aids in reducing errors. Leveraging its understanding of your existing code and comments, it offers contextually relevant suggestions, minimizing the likelihood of syntactical or logical mistakes. By guiding you towards optimized code structures, it helps maintain code integrity and enhances overall software quality.
The user experience with CodeWhisperer is designed to be user-friendly and intuitive. Its integration into your preferred development environment is seamless, ensuring a smooth transition into incorporating this powerful code generation tool into your workflow. With its ease of use and ability to adapt to various programming languages and frameworks, CodeWhisperer caters to a wide range of developers, regardless of their expertise level.
In summary, CodeWhisperer revolutionizes the coding experience by leveraging machine learning to provide real-time code recommendations. It enables faster coding, improved productivity, reduced errors, and offers an intuitive user experience. By harnessing the power of CodeWhisperer, developers can unleash their creativity, optimize their coding workflow, and build high-quality software more efficiently.
04/09 AgentGPT
AgentGPT is an innovative platform that empowers users to design, modify, and launch customized AI agents. Drawing upon the advancements of ChatGPT and AutoGPT methodologies, AgentGPT offers a versatile solution for creating self-directed AI agents with specific objectives. With this platform, users have the flexibility to assign personalized names to their AI agents and define the tasks and goals they wish to pursue. Whether it’s developing chatbots or automating various processes, AgentGPT provides the necessary tools and infrastructure to configure and deploy autonomous AI agents.
One of the key strengths of AgentGPT lies in its user-friendly interface, which eliminates the requirement for extensive programming expertise. This accessibility enables a broader range of individuals to engage with the platform and simplifies the overall process of creating and deploying AI agents. By removing technical barriers, AgentGPT empowers users to leverage the capabilities of AI and explore its potential in various applications and domains. Through its intuitive interface and powerful functionality, AgentGPT opens up new avenues for individuals to harness the power of AI and realize their creative ideas.
04/07 Generative Agents

In their research paper titled “Generative Agents: Interactive Simulacra of Human Behavior,” the authors delve into the concept of generative agents, which are computational software designed to simulate human behavior in a believable manner. These agents find applications in a wide range of interactive scenarios, such as immersive environments, rehearsal spaces for interpersonal communication, and prototyping tools.
The architecture of generative agents builds upon a foundation of a large language model that stores a comprehensive record of the agent’s experiences using natural language. This allows the agent to synthesize and integrate these memories over time, resulting in higher-level reflections. The agents can dynamically retrieve these reflections to plan their behavior accordingly.
One key aspect of generative agents is their ability to produce both believable individual behaviors and emergent social behaviors. By leveraging the components of the agent architecture, namely observation, planning, and reflection, the agents are able to generate behavior that appears realistic to human observers.
To demonstrate the effectiveness of their approach, the authors instantiate generative agents in an interactive sandbox environment inspired by the popular simulation game, The Sims. In this environment, end users can engage with a small town populated by twenty-five agents, interacting with them using natural language. Through an evaluation process, the generative agents exhibit behaviors that are deemed believable and authentic.
The authors further validate the importance of each component of the agent architecture by conducting ablation experiments. These experiments reveal that observation, planning, and reflection play crucial roles in enhancing the believability of the generative agents’ behavior.
Overall, the research presented in the paper showcases the potential of generative agents as interactive simulacra of human behavior. By leveraging language models and incorporating key architectural components, these agents offer promising opportunities for creating realistic and engaging interactive experiences.
04/05 Data Leakage
The paper titled “Efficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset” by Yeshwanth Kumar Adimoolam, Bodhiswatta Chatterjee, Charalambos Poullis, and Melinos Averkiou delves into the issues prevalent in the CrowdAI Mapping Challenge Dataset. The authors specifically address concerns related to incorrect and low-quality annotations, the abundance of duplicated image samples, and the presence of data leakage between the training and testing splits.
To combat these challenges, the authors propose an easily implementable pipeline that capitalizes on perceptual hashing techniques to detect and handle duplicate instances efficiently and identify cases of data leakage within the dataset. The primary objective of their proposed approach is to offer a user-friendly solution for deduplication and leakage detection in large-scale image datasets.
The pipeline suggested in the paper relies on collision detection of perceptual hashes of images to facilitate effective deduplication. When applied to the CrowdAI Mapping Challenge Dataset, which consists of approximately 280,000 training images and 60,000 testing images, the authors discovered that nearly 250,000 images (roughly 90% of the training split) were identical.
The paper provides a thorough explanation of the proposed pipeline and its implementation. It outlines the various steps involved in the deduplication process, elucidates the underlying principles of perceptual hashing, and presents experimental results that demonstrate the efficacy of their approach in tackling duplication and leakage issues within the CrowdAI Mapping Challenge Dataset.
In conclusion, the paper offers a solution to address the problems of low-quality annotations, extensive duplication, and data leakage in the CrowdAI Mapping Challenge Dataset. The proposed pipeline, which leverages perceptual hashing techniques, presents an efficient methodology for deduplication and leakage detection in large-scale image datasets.
04/04 Children Drawing
Animated Drawings is an innovative project that utilizes cutting-edge technologies such as object detection models, pose estimation models, and image processing-based segmentation methods. The main objective of this project is to transform a hand-drawn image into a digital version and then animate it using traditional computer graphics techniques. Developed by Meta AI Research, the project is open-source and can be accessed through their website, providing a valuable creative tool for users to bring their own drawn characters to life.
To ensure smooth installation and usage, the project has been tested on macOS Ventura 13.2.1 and Ubuntu 18.04. However, users may encounter compatibility issues when installing it on other operating systems. The project recommends activating a Python virtual environment before installing Animated Drawings, with Conda’s Miniconda being a recommended choice. Detailed instructions on downloading and installing Miniconda can be found on the project’s website.
By adjusting the configuration files, users can achieve various effects with Animated Drawings. More information about the available configuration options and their functionalities can be accessed on the project’s website, allowing users to explore and experiment with different settings to customize their animated creations.
04/03 Koala after LLaMA
Koala is an advanced chatbot developed through the fine-tuning of Meta’s LLaMA using dialogue data obtained from various online sources. This chatbot has demonstrated its ability to generate responses that are often preferred over Alpaca and, in many cases, are on par with ChatGPT. The training data for Koala was carefully curated to include interactions involving highly capable closed-source models like ChatGPT, thereby enhancing its performance. The resulting model, known as Koala-13B, has been evaluated through human assessments using real-world user prompts, showing competitive performance when compared to existing models. The authors of this research project propose that smaller models, such as Koala, when trained on meticulously sourced data, can achieve similar performance to larger models. However, it’s important to note that Koala is still a research prototype and has significant limitations in terms of content, safety, and reliability. Therefore, it is strongly advised not to use Koala outside of research purposes.
04/02 JARVIS (Auto-GPT)
HuggingGPT is a framework that utilizes large language models (LLMs) to connect different AI models within the machine learning community in order to tackle complex AI tasks. The framework relies on LLMs to act as controllers, overseeing existing AI models and utilizing language as a universal interface to facilitate this coordination.
When a user submits a request, HuggingGPT employs ChatGPT for task planning. It selects suitable AI models based on their function descriptions available in Hugging Face, the platform that hosts a wide range of AI models. The framework then executes each subtask using the selected AI model and summarizes the response based on the execution results.
The strength of HuggingGPT lies in its ability to harness the powerful language capabilities of ChatGPT and the extensive collection of AI models available in Hugging Face. This enables HuggingGPT to address a wide array of sophisticated AI tasks across various modalities and domains, yielding impressive outcomes in language processing, computer vision, speech recognition, and other challenging areas.
Thanks for Reading.
Thank you for reading the May 25th Age of Intelligence Newsletter! Here’s a brief overview of the main topics covered:
- Discovering Symbolic Models from Deep Learning with Inductive Biases (2020): This paper introduces a method for extracting symbolic models from deep learning architectures, enhancing interpretability and discovering new physical relationships.
- Perplexity.ai: A cutting-edge AI technology that uses GPT-3 and a large language model to provide users with an advanced search experience, delivering highly accurate search results.
- Aria (AI Browser): Opera introduces Aria, an AI-powered browser designed to enhance creativity and productivity, utilizing generative AI and incorporating features like live web results.
- AI Robots race begins: Boston Dynamics upgrades its robot dog, Spot, with new software and hardware features aimed at improving its performance in industrial settings.
- Google Ads AI: Google Marketing Live 2023 unveils new generative AI capabilities for Google Ads, empowering marketers to make informed decisions, solve problems, and unleash their creativity.
- Windows Copilot: Microsoft announces Windows Copilot, an AI-powered assistance system that helps users accomplish tasks efficiently through Bing Chat and plugins.