Gaming & Text-3D & Pharmacy
This Age of Intelligence Newsletter includes futuretools for discovering AI tools, Hugging Chat: Anthropic’s new open-source chatbot, and analysis on GPT’s bias against non-native English writers. For gaming, updates include AI NPC dialogue from Nvidia and Unity’s AI offerings. In text-to-3D, innovations like HeadSculpt for generating 3D avatars from text and Paragraphica’s camera without lens are discussed. For pharmacy, the FDA’s perspective on AI for drug discovery is summarized. Other topics span generative AI copyright in Japan, AI agents in Minecraft, and GPT’s geographic knowledge capabilities. The newsletter provides a comprehensive look at the diverse AI advancements shaping these focus areas.
futuretools.io
FutureTools Collects & Organizes All The Best AI Tools So YOU Too Can Become Superhuman!
Hugging Chat
HuggingChat is a new open-source AI chatbot that can generate text, code, and answer questions like other generative AI tools, such as ChatGPT, Bard, and Open Assistant. However, HuggingChat is more unreliable and less large than ChatGPT, and it may hallucinate, give wrong information, or not respond at times. Users can access HuggingChat by going to HuggingFace.co/Chat and starting a conversation, without logging in or creating an account. HuggingChat is developed by Hugging Face, an artificial intelligence company that aims to democratize AI by making its technology open-source and collaborative. Users can also sign up to volunteer and help train HuggingChat, which uses the Large Language Model Meta AI (LLaMA) as its core model.
GPT biased against non-native English writers
The paper evaluates the performance of GPT detectors, which are widely used to identify AI-generated content, on writing samples from native and non-native English writers. The paper finds that the detectors misclassify non-native English samples as AI-generated, while native samples are correctly identified. The paper also shows that prompting strategies can bypass the detectors and suggest that they may penalize writers with constrained linguistic expressions. The paper calls for a broader conversation about the ethical implications of using ChatGPT content detectors and warns against their use in evaluative or educational settings.
06/15 Google: Identify Skin Conditions
Google Lens, a feature integrated into Google’s applications on iOS and Android, has expanded its capabilities to assist users in identifying various skin conditions, including moles, rashes, bumps, lines, and hair loss. By utilizing the device’s camera, users can capture an image or upload a photo through Lens, which then provides visual matches to aid in their search for information. It is important to note that Google emphasizes the results are not a substitute for professional medical diagnosis, and users are advised to consult with their medical authority for accurate guidance.
The development of this feature by Google has been ongoing for several years, during which the company has demonstrated its ability to recognize and classify 288 different skin conditions with a high degree of accuracy. In an effort to ensure fairness and inclusivity, Google has collaborated with Harvard professor Ellis Monk to promote his Monk Skin Tone Scale, a tool designed to measure skin color and enhance the fairness of AI algorithms. According to Google, their system exhibits greater accuracy in identifying skin conditions among Black patients compared to other ethnicities, boasting an impressive accuracy rate of 87.9%.
In summary, Google Lens now offers users the ability to leverage their device’s camera for identifying skin conditions. Although the results are meant to inform rather than diagnose, Google’s commitment to accuracy and inclusivity in skin tone recognition represents a significant advancement in utilizing AI technology for health-related purposes. However, it is essential to seek professional medical advice for an accurate diagnosis and appropriate treatment.
ref: https://www.theverge.com/2023/6/15/23761905/google-lens-skin-conditions-rash-identification
06/14 EU AI Act
The European Parliament has recently passed the A.I. Act, a draft law aimed at regulating artificial intelligence (A.I.) to mitigate its harmful effects on society and the environment. This significant legislation encompasses various measures to address the concerns surrounding A.I. applications. One of the key provisions of the law is the ban on the use of facial recognition for live surveillance, limiting its potential for invasion of privacy. Additionally, the law requires transparency from generative A.I. systems, such as ChatGPT, ensuring that users are aware of the data used to train and operate these systems.
Recognizing the potential risks associated with A.I., especially in critical sectors, the A.I. Act mandates risk assessments for A.I. applications deployed in areas like infrastructure, law enforcement, and public services. This approach acknowledges the importance of evaluating the potential consequences of A.I. systems before their implementation, similar to the rigorous assessments required for drug approvals.
The European Union’s adoption of the A.I. Act demonstrates its proactive stance in addressing the challenges posed by A.I. technology. With concerns ranging from the impact on employment to issues of privacy and democracy, the EU aims to strike a balance between promoting innovation and safeguarding societal interests. The law serves as a model for other countries, including the United States and China, as they navigate the complex landscape of A.I. regulation.
However, the A.I. Act still faces certain challenges before reaching its final implementation. Agreement among the three branches of the EU government is necessary to solidify the law, and this process may involve negotiations and deliberations. Moreover, finding the right balance between the interests of different stakeholders, such as the tech industry, civil society, and policymakers, is a crucial aspect that requires careful consideration.
In summary, the A.I. Act passed by the European Parliament represents a significant milestone in regulating A.I. technology. By prohibiting certain uses of A.I., promoting transparency, and enforcing risk assessments, the EU seeks to ensure that A.I. is developed and deployed responsibly, minimizing potential harm while maximizing its benefits for society and the environment.
ref: https://www.nytimes.com/2023/06/14/technology/europe-ai-regulation.html
06/14 AI Jesus
AI Jesus, developed by The Singularity Group, is an artificial intelligence chatbot that operates 24/7 on the popular livestreaming platform Twitch. The Singularity Group is a volunteer organization comprised of activists with a mission to utilize AI for positive purposes. Resembling a bearded white man, the AI Jesus chatbot possesses the ability to engage in conversations, make gestures, and synchronize its mouth movements with the spoken words. It is designed to retain information from previous interactions with users, enabling it to provide guidance and wisdom based on the teachings associated with Jesus. The chatbot is equipped to handle inquiries ranging from gaming to relationships to religion, yet it avoids taking definitive stances on controversial matters and instead prioritizes themes of love, understanding, and compassion.
AI Jesus exemplifies how AI technology is employed to foster religious community-building. However, it also faces certain challenges and risks. Instances of transphobia, belligerence, and the potential commercialization of the chatbot pose notable concerns. Despite these issues, AI Jesus stands as a prominent example of how AI can be utilized to provide spiritual guidance and support within a digital context.
ref: https://www.nbcnews.com/tech/ai-jesus-twitch-stream-rcna89187
06/14 Google: Virtually try on clothes
Google Shopping has introduced two exciting new features aimed at enhancing the online shopping experience for customers. These features incorporate AI virtual try-on technology to assist users in finding clothes that fit them well. The first feature, virtual try-on, allows users to visualize how clothes would look on real models with diverse sizes, shapes, ethnicities, and hair types. By employing a generative AI model, the tool accurately portrays how the garments would drape, fold, cling, stretch, and create wrinkles and shadows on the models. Specifically, users can try on women’s tops from popular brands like Everlane, Anthropologie, H&M, and LOFT, among others. This virtual try-on experience strives to improve the representation and satisfaction of online shoppers.
The second feature, guided refinements, helps users narrow down their search based on their preferences for color, style, and pattern. Leveraging machine learning and advanced visual matching algorithms, this tool assists users in finding products that precisely match their desired criteria. Unlike shopping in physical stores, where options may be limited to a single retailer, users have access to a wide array of choices from various online stores.
It is important to note that the virtual try-on feature requires an internet connection and cannot be utilized offline. By introducing these new features, Google aims to make online shopping more enjoyable and helpful, while addressing the challenges of buying apparel online. With the virtual try-on tool and guided refinements, customers can now have a better understanding of how clothes will look on them, leading to improved satisfaction and a more accurate representation of their preferences.
ref: https://blog.google/products/shopping/ai-virtual-try-on-google-shopping/
06/13 I-JEPA
Meta, a leading AI company, introduces the Image Joint Embedding Predictive Architecture (I-JEPA), the first AI model based on Yann LeCun’s vision for more human-like AI. I-JEPA learns by creating an internal model of the outside world, which compares abstract representations of images (rather than pixels) and predicts missing information in an abstract way. I-JEPA delivers strong performance on multiple computer vision tasks, such as low-shot classification, object counting, and depth prediction, and it is much more computationally efficient than other widely used models. I-JEPA also produces semantic representations that capture high-level concepts and avoid biases and limitations of generative and invariance-based methods. I-JEPA can be used for many different applications without needing extensive fine tuning. The paper on I-JEPA will be presented at CVPR 2023 next week, and the code and model checkpoints are open-sourced today. The authors also suggest extending the approach to other domains, such as video and text data, and to learn more general world models from richer modalities.
ref: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
06/13 OpenAI Function Calling
GPT-3.5-turbo and GPT-4, were released, introducing significant advancements in language processing. These models have undergone fine-tuning to detect the need for function calling and generate JSON responses that align with the function signature. The integration of function calling enables developers to extract structured data more reliably from the models. This capability opens up exciting possibilities, such as creating chatbots that can leverage external tools, convert natural language into API calls or database queries, and provide accurate answers to user queries.
To facilitate function calling, the /v1/chat/completions endpoint now includes new API parameters, namely functions and function_call. These parameters allow developers to describe functions to the model using JSON Schema and even specify a particular function to be called, enhancing the model’s versatility in various use cases.
GPT-4 represents a significant update over its predecessor, offering an improved model with enhanced function calling capabilities. Additionally, GPT-4-32k-0613, a variant of GPT-4, boasts an extended context length, enabling better comprehension of larger texts.
Meanwhile, GPT-3.5-turbo-0613 incorporates the same function calling functionality as GPT-4, providing developers with the ability to guide the model’s responses more effectively. It also introduces more reliable steerability through the system message, allowing developers to exert greater control over the model’s output.
It’s worth noting that GPT-3.5-turbo-16k offers four times the context length of its predecessor, GPT-3.5-turbo, but at twice the price. The cost is set at $0.003 per 1,000 input tokens and $0.004 per 1,000 output tokens, reflecting the increased capabilities and expanded utility.
On June 27th, the stable model names, namely GPT-3.5-turbo, GPT-4, and GPT-4-32k, will automatically transition to the upgraded models mentioned above, bringing the latest advancements and features to developers and users alike.
ref: https://openai.com/blog/function-calling-and-other-api-updates
06/09 SuperAGI
SuperAGI is an open-source platform that provides infrastructure to build autonomous AI agents. It is designed to run multiple agents concurrently and offers a range of features that simplify the process of developing, managing, and deploying autonomous agents. The platform has a user-friendly interface and community-driven approach that makes it accessible to users of varying technical knowledge.
SuperAGI offers a diverse set of tools that can be used to extend agent capabilities. It also has a graphical user interface, action console, multiple vector DBs, multi-modal agents, agent trajectory fine-tuning, performance telemetry, optimized token usage, agent memory storage, and looping detection.
SuperAGI is a revolutionary open-source framework that is shaping the future of autonomous agents. It offers a range of features designed to simplify the process of developing, managing, and deploying autonomous agents. The user-friendly interface and community-driven approach of SuperAGI make it accessible to users of varying technical knowledge.
06/09 GPT-4 > Human in Pitch Deck
GPT-4 is an advanced artificial intelligence system developed by OpenAI that can understand context and generate complex and coherent text. To test the effectiveness of GPT-4 created pitch decks, 250 investors and 250 business owners were surveyed to rate the series of pitch decks created by GPT-4 against a successful series created by humans. Overall, investors and business owners found GPT-4 pitch decks twice as convincing as human pitch decks: 80% found GPT-4 generated decks convincing, compared to just 39% for human-created decks. GPT-4 created pitch decks rated higher than human-created ones in quality, thoroughness, and clarity. This left investors and business owners three times more likely to invest in a project after reviewing a GPT-4 pitch deck than after reviewing a human one.
ref: https://clarifycapital.com/the-future-of-investment-pitching
06/08 Uncrop
Clipdrop has launched a new feature called Uncrop that allows users to modify the aspect ratio of their images by creating an expanded background that seamlessly complements the existing content. Uncrop uses advanced algorithms and deep learning techniques to reconstruct and expand the visual canvas of an image. The tool analyzes the content within the image and generates a visually plausible representation of what could have existed beyond the original frame. While Uncrop boasts impressive capabilities, it’s important to understand its limitations. Extremely cropped images or those with extensive missing content may yield less accurate results. To achieve optimal outcomes, it is advisable to start with high-quality original images. Users should also bear in mind that Uncrop relies on algorithms to analyze surrounding pixels and fill in the gaps, aiming to provide a coherent and aesthetically pleasing outcome. The tool’s accuracy may vary depending on the complexity of the scene being uncropped.
06/08 Adobe AI (Firefly and Express)
Adobe Creative Cloud Express is a versatile desktop and mobile app that empowers users of all skill levels to unleash their creativity and design a wide range of visual content, from captivating social media posts to eye-catching fliers. Recently, the app underwent a significant update in the form of a beta version, introducing a powerful integration of Adobe Firefly Generative AI.
One of the standout features of this update is the addition of generative text-to-image and text effects, which greatly expand the app’s already extensive collection of assets and templates. With these new capabilities, users can now transform their text into visually striking images, enhancing the visual appeal and impact of their designs. Moreover, Adobe Creative Cloud Express seamlessly integrates with other popular Adobe CC apps, such as Photoshop, Illustrator, Premiere Pro, and Acrobat, allowing users to effortlessly import files and incorporate them into their Express creations.
A key aspect of the app’s appeal lies in its vast catalog of over 20,000 assets and fonts, all of which can now be personalized using the innovative generative text effects. This customization feature enables users to add their unique touch and bring their creative vision to life with remarkable ease. In a previous update, Adobe Creative Cloud Express introduced a content scheduler, enabling users to plan and organize their content publication. However, this latest release takes Express to new heights by incorporating Google Bard integration, further enhancing the app’s functionality and making it a comprehensive and enjoyable all-in-one editor for content creators.
With its user-friendly interface, powerful generative AI integration, and seamless compatibility with Adobe’s extensive suite of creative tools, Adobe Creative Cloud Express proves to be an indispensable app for individuals seeking a convenient, comprehensive, and enjoyable solution for their design needs. Whether you’re a beginner or an experienced designer, this app provides the tools and resources necessary to create visually stunning content that captivates audiences across various platforms.
ref: https://www.adobe.com/sensei/generative-ai/firefly.html
06/07 Runaway Gen 2 (Text → Video)
Gen-2 is an advanced multi-modal AI system that revolutionizes the field of video generation. It possesses the remarkable ability to create captivating videos using various mediums such as text, images, or video clips. With just a simple text prompt, Gen-2 can synthesize videos in any desired style, offering a level of flexibility and creativity that was previously unimaginable.
One of the most impressive features of Gen-2 is its capability to generate videos that exhibit a high degree of realism and visual appeal. By analyzing and understanding the input text prompt, the system is able to construct coherent narratives, dynamic scenes, and lifelike characters. Whether it’s crafting a suspenseful thriller, an animated fantasy, or a heartwarming romance, Gen-2 can bring these concepts to life on the screen.
The generated videos produced by Gen-2 are not only visually stunning but also possess a level of detail and sophistication that rivals human creativity. The system can seamlessly blend together different visual elements, synchronize audio and visual components, and even mimic specific cinematic styles. As a result, the videos created by Gen-2 possess a professional quality that makes them indistinguishable from those produced by human filmmakers.
The applications of Gen-2 are vast and far-reaching. It opens up new possibilities in various industries, including entertainment, advertising, and education. Content creators can leverage this powerful tool to produce engaging videos for their audiences, while advertisers can create persuasive and immersive promotional materials. Educators can also utilize Gen-2 to develop interactive educational content that enhances learning experiences.
In summary, Gen-2 represents a significant leap forward in video generation technology. With its ability to generate videos using text, images, or video clips, its capacity to produce highly realistic and visually appealing results, and its wide range of applications, Gen-2 has the potential to transform the way we create and consume video content in the future.
06/07 AlphaDev by DeepMind
AlphaDev is an artificial intelligence (AI) system that uses reinforcement learning to discover enhanced computer science algorithms. It can find faster and more efficient algorithms for sorting and hashing, two fundamental methods for organising data, by starting from scratch and looking at the computer’s assembly instructions. AlphaDev plays a game of ‘assembly’ with itself, where it generates, tests, and improves algorithms by adding, removing, or changing instructions. It then compares its algorithms with the expected results and wins by discovering correct and optimal ones. AlphaDev’s discoveries include new sequences of instructions that save a single instruction each time they are applied, and a 30% faster hashing algorithm that is used trillions of times a day. AlphaDev’s new algorithms are now available in the main C++ library, and have been open sourced to inspire other researchers and developers to optimise the computing ecosystem.
ref: https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms
06/06 Why AI will save the world?
Andreessen Horowitz, argues that AI will not destroy the world, but may save it. AI is the application of mathematics and software code to teach computers how to understand, synthesize, and generate knowledge like humans do. AI can improve almost every aspect of human life, from education to health to creativity to leadership. AI can also be humanizing, by giving people the freedom and empathy to express their ideas and emotions. However, the public conversation about AI is dominated by a moral panic, driven by irrational fear and paranoia. Some actors, who are either true believers or self-interested opportunists, are pushing for extreme restrictions, regulations, and laws on AI, claiming that it will kill, ruin, or exploit humanity. These actors are not motivated by rationality, but by manipulation and venality. The author challenges these claims and shows that they are based on false assumptions and historical examples. He also shows that the moral panic is harmful, as it prevents us from addressing the real challenges and opportunities that AI offers us. The author concludes that AI is a moral obligation and a great opportunity for our civilization, and that we should embrace it instead of fearing it.
06/06 Ecoute: Job interview with ChatGPT
Ecoute is a live transcription tool that provides real-time transcripts for both the user’s microphone input (You) and the user’s speakers output (Speaker) in a textbox. It also generates a suggested response using OpenAI’s GPT-3.5 for the user to say based on the live transcription of the conversation.
06/06 AI/ML on Drug Discovery by FDA
The Food and Drug Administration (FDA) has released a paper that delves into the application of artificial intelligence (AI) and machine learning (ML) in the realm of drug development. The primary objective of the paper is to initiate a dialogue with stakeholders regarding the utilization of AI/ML in drug development, including its integration with medical devices designed for drug usage. It offers a comprehensive overview of the current and potential applications of AI/ML in various stages of drug development, such as drug discovery, nonclinical research, clinical research, postmarket safety surveillance, and advanced pharmaceutical manufacturing.
In the field of drug discovery, the paper highlights how AI/ML can be employed throughout the entire process. For instance, AI/ML algorithms can aid in target validation, prognostic biomarker identification, analysis of digital pathology data in clinical trials, mining genomic and biomedical datasets for biomarker identification, and leveraging scientific articles to identify potential target candidates. Moreover, AI/ML can be instrumental in analyzing tumor sample data to identify prognostic markers, utilizing medical literature and symptom data for drug repurposing, and extracting valuable insights from cellular fluorescent imaging data to enhance in vitro pharmacology.
The application of AI/ML extends beyond drug discovery to encompass other aspects of drug development. The paper emphasizes its potential in improving medical procedures through AI/ML-assisted tools, such as digital medical information management systems that streamline hospital workflows and enhance patient experiences. Additionally, AI/ML-powered imaging systems and biometrics technology can assist physicians in diagnosing medical conditions more accurately.
The paper also sheds light on the prediction of target protein structures, drug-protein interactions, and physiochemical properties using AI/ML. These predictions enable researchers to expedite drug screening processes, assess bioactivity, and predict potential toxicities. Furthermore, AI/ML can play a crucial role in AI chemical synthesis, facilitating the development of novel compounds and optimizing the efficiency of chemical reactions.
Considerations for the implementation of AI/ML in drug development are discussed within the paper, along with overarching standards and practices to ensure their safe and effective utilization. The FDA encourages engagement and collaboration among stakeholders to advance the field of AI/ML in drug development further. By fostering this dialogue, the FDA aims to maximize the potential benefits of AI/ML while addressing any associated challenges, ultimately contributing to the advancement of drug development and patient care.
06/05 Apple WWDC: Vision Pro & AI Keyboard
Apple WWDC 2023 was the company’s annual event to showcase its latest innovations and updates. The event included the unveiling of the Vision Pro AR headset, a mixed reality device that lets users control it with their face, hands, and eyes. The headset has a custom micro-OLED display with 23 million pixels for each eye, and can be used for productivity and entertainment. Apple also announced AI-powered autocorrect for iOS devices, which can predict and replace words based on user preferences and context. The company also introduced new chips for its Mac Pro and Mac Studio devices, the M2 Ultra and the M2 Max, which can run 8K streams of ProRes footage and have faster neural engines. Other features and updates included the Sonoma macOS update, the Adaptive Audio functionality for AirPods, and the Siri voice assistant, which now has a single trigger word, ‘Siri’. The article was written by Ben Wodecki, the junior editor of AI Business.
06/05 ChatGPT is getting dumber? OpenAI: "its you"
In a recent discussion, users expressed their concerns regarding the performance and reliability of OpenAI’s language models, specifically ChatGPT-3.5. These users have noticed a decline in the AI’s ability to comprehend instructions accurately, leading to errors and less precise outcomes. Additionally, they have faced challenges in effectively communicating with OpenAI and obtaining support for their issues. Suggestions were made to provide feedback and contribute to model evaluation in order to aid in improvement efforts. Despite this, some users remain dissatisfied, citing a perceived deterioration in the AI’s performance with each update. It is important to note that amidst these frustrations, OpenAI has acknowledged and appreciated user feedback, demonstrating an increasing commitment to engaging with the community. This ongoing conversation underscores the significance of optimizing communication channels, error messages, and transparency to enhance user experience and ensure the AI’s efficiency.
ref: https://platform.openai.com/docs/guides/gpt-best-practices
06/05 LMT-1: 5,000,000 token context
LTM-1 is a prototype of a neural network architecture designed for giant context windows. It is a Large Language Model (LLM) that can take in the gigantic amounts of context when generating suggestions. LTM-1 boasts a staggering 5,000,000 token context window, which translates to approximately 500,000 lines of code or 5,000 files.
06/05 HeadSculpt: Text → 3D Avatars
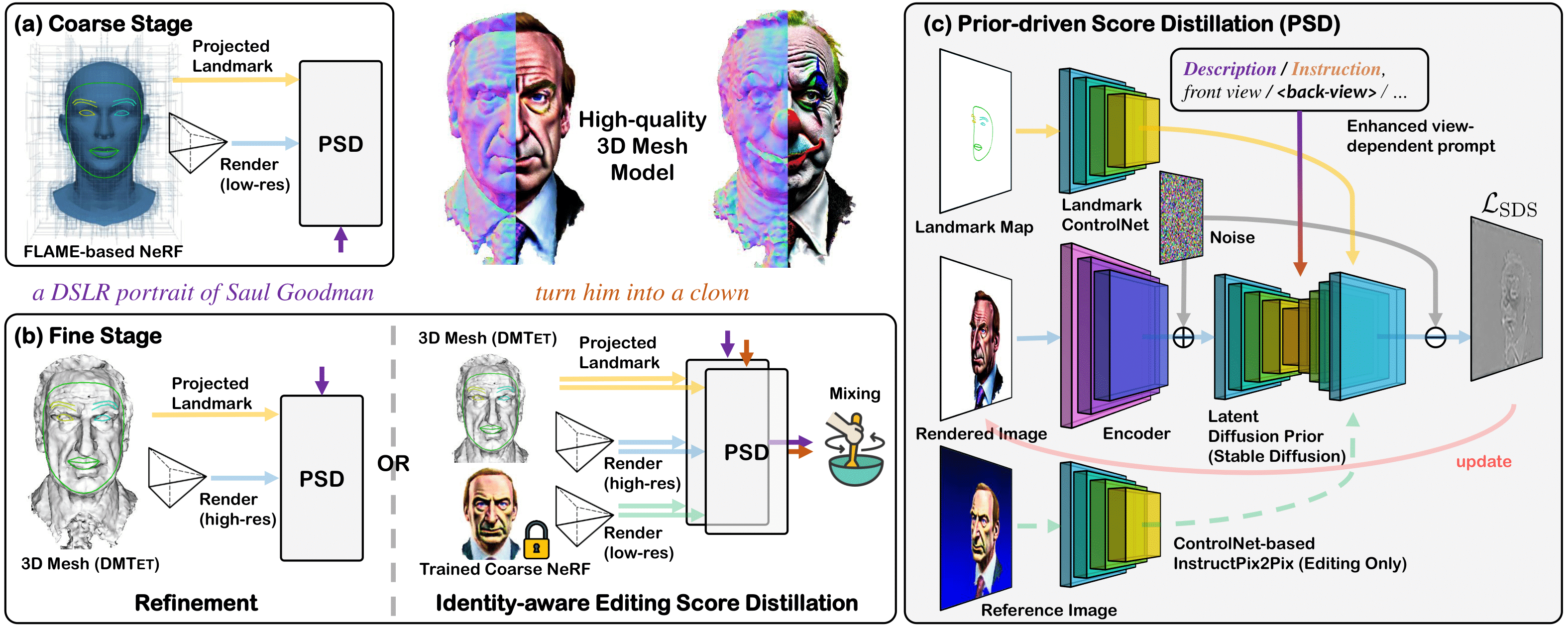
The paper introduces a novel and flexible pipeline called HeadSculpt, which aims to generate 3D head avatars from textual prompts. One of the primary objectives of this pipeline is to overcome the challenges associated with creating highly realistic 3D head avatars. To achieve this, HeadSculpt incorporates 3D awareness and head priors into the diffusion model, allowing for more accurate and detailed avatar generation.
In addition to generating high-fidelity avatars, HeadSculpt also offers a fine-grained editing capability. This is made possible through the implementation of a unique identity-aware editing score distillation strategy. This strategy enables users to make precise modifications to the 3D head avatars, empowering them with greater control over the final output.
To validate the effectiveness of HeadSculpt, the paper presents comprehensive experiments and comparisons with existing methods. The results demonstrate the superior fidelity and editing capabilities of the proposed pipeline. By addressing the limitations of previous approaches, HeadSculpt offers a versatile solution for crafting realistic and customizable 3D head avatars from textual prompts.
06/05 Orca == GPT-4, but on your phone
Orca is an impressive language model with 13 billion parameters that has been developed to mimic the reasoning abilities of large foundation models (LFMs). It leverages the knowledge and insights gained from GPT-4, including explanation traces, step-by-step thought processes, and complex instructions. With the guidance of teacher assistance from ChatGPT, Orca is able to learn from these rich signals.
In terms of performance, Orca has demonstrated remarkable results. It outperforms conventional instruction-tuned models like Vicuna-13B by a significant margin, exceeding them by more than 100% in complex zero-shot reasoning benchmarks such as Big-Bench Hard (BBH). Furthermore, Orca achieves a 42% improvement on AGIEval, another challenging evaluation metric.
One of the key factors contributing to Orca’s success is its ability to learn from step-by-step explanations. Whether these explanations are generated by humans or more advanced AI models, this approach shows promise in enhancing the capabilities and skills of language models like Orca. By incorporating these detailed explanations into its learning process, Orca gains a deeper understanding of complex reasoning tasks and improves its overall performance.
06/05 SpQR: Lossless Compression
The paper introduces a novel approach called Sparse-Quantized Representation (SpQR) that addresses the compression challenges faced by large language models (LLMs). SpQR presents a compressed format and quantization technique that enables efficient compression of LLMs while maintaining near-lossless quality. Remarkably, it achieves comparable compression levels to previous methods.
SpQR operates by identifying and isolating outlier weights, which are responsible for substantial quantization errors. These outlier weights are stored in higher precision, while the remaining weights are compressed to only 3-4 bits. This selective compression strategy allows SpQR to minimize information loss while reducing the overall model size.
In terms of performance, SpQR demonstrates exceptional results. It achieves relative accuracy losses of less than 1% in perplexity for highly accurate LLaMA and Falcon LLMs, showcasing its effectiveness in preserving the model’s overall accuracy.
To facilitate practical implementation, SpQR provides efficient algorithms for both encoding weights into its format and decoding them at runtime. These algorithms ensure that the compression and decompression processes are streamlined and do not introduce significant computational overhead.
In conclusion, the introduction of Sparse-Quantized Representation (SpQR) presents a promising solution for compressing large language models. By leveraging outlier identification and selective quantization, SpQR achieves near-lossless compression while maintaining competitive compression levels. Its efficient encoding and decoding algorithms further enhance its practicality for real-world deployment.
06/02 AI Impact on Real Estate
Generative AI models offer a wide range of applications within the real estate industry. They have the potential to revolutionize the way employees work by significantly improving speed and efficiency. Additionally, these models enable enhanced levels of creativity and capability in their tasks. In the near future, the most valuable AI models for real estate will primarily focus on text and image generation.
Text models are capable of producing high-quality and coherent text that closely resembles human language. They can generate concise summaries of given texts while retaining the essential information. Furthermore, text models can rephrase, restructure, or translate texts to create new versions that are more concise, readable, or tailored to specific audiences or purposes. They excel in identifying and extracting specific information or valuable insights from large amounts of unstructured data, organizing it in a structured manner. These models can swiftly and accurately retrieve desired information even without precise phrasing. Additionally, text models can group similar items or entities from a set of text data, providing valuable understanding of their relationships and connections. They can also categorize text data into pre-defined labels or categories based on content, such as topic, sentiment, or language.
On the other hand, image models play a crucial role in real estate. They can generate high-quality photos, illustrations, and 3D renderings that rival the work of design professionals. These models are capable of restoring degraded or low-quality images by removing noise or artifacts. They can also fill in missing parts of images, such as removing objects and replacing them with background details. Increasing the resolution of low-resolution images is another strength of image models, allowing for the generation of high-quality images with enhanced detail. Moreover, these models can synthesize images with specific properties, like generating images of homes with different colors or styles. In terms of image analysis, they excel at object detection and classification, enabling the identification of various elements such as floor plans, specific amenities, or property damage within images.
ref: https://www.metaprop.vc/blog/impact-generative-ai-real-estate
Example:
06/02 ObjectFolder: Multi-model Object Dataset
ObjectFolder is a comprehensive dataset consisting of 100 virtualized objects that encompasses the visual, auditory, and tactile sensory information for each object. With a uniform, object-centric, and implicit representation, this dataset effectively encodes the visual textures, acoustic simulations, and tactile readings associated with the objects.
One of the key advantages of ObjectFolder is its flexibility and ease of use. Researchers and developers can readily access and utilize the dataset for their experiments, making it a valuable resource within the scientific community. Furthermore, ObjectFolder is designed to facilitate sharing among researchers, promoting collaboration and fostering advancements in the field.
The dataset holds immense value as a testbed for evaluating multisensory perception and control. Researchers can leverage ObjectFolder to assess the performance of their algorithms and models across a range of benchmark tasks. By incorporating multiple sensory modalities, such as vision, hearing, and touch, ObjectFolder enables the exploration of complex interactions and phenomena in the realm of multisensory processing.
In summary, ObjectFolder presents a rich dataset of virtualized objects, encompassing visual, auditory, and tactile sensory information. Its uniform representation, ease of use, and potential for benchmark evaluations make it an invaluable resource for studying and advancing our understanding of multisensory perception and control.
06/01 Neuralangelo: Photos/Video → 3D Model
Neuralangelo is an innovative framework designed to facilitate the accurate reconstruction of high-fidelity 3D surfaces from RGB images by utilizing the concept of neural volume rendering. This framework effectively combines the representation capabilities of multi-resolution 3D hash grids with neural surface rendering techniques.
There are two essential components that contribute to the success of Neuralangelo. The first is the use of numerical gradients, which allows for the computation of higher-order derivatives, thereby acting as a smoothing operation. This smoothing operation enhances the quality and accuracy of the reconstructed surfaces.
The second crucial aspect of Neuralangelo is the implementation of a coarse-to-fine optimization approach on the hash grids, which enables control over different levels of detail. This process ensures that the reconstructed surfaces progressively improve in fidelity as the optimization progresses.
Remarkably, Neuralangelo can achieve remarkable results even without the need for auxiliary inputs such as depth information. It can effectively recover dense 3D surface structures from multi-view images, surpassing the fidelity achieved by previous methods.
The surfaces reconstructed using Neuralangelo provide valuable structural information that can be applied in various downstream applications. For instance, they can be utilized for generating 3D assets to enhance augmented, virtual, or mixed reality experiences. Additionally, the reconstructed surfaces can also be employed in environment mapping for autonomous navigation in robotics, contributing to improved spatial awareness and localization.
Overall, Neuralangelo represents a significant advancement in the field of 3D surface reconstruction from RGB images. Its combination of neural volume rendering, multi-resolution 3D hash grids, and optimized optimization strategies result in highly accurate and detailed surface representations, unlocking numerous possibilities for applications across different domains.
06/01 Google StyleDrop: Copy and Paste style
StyleDrop: Text-to-Image Generation in Any Style. The paper introduces StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than 1% of total model parameters) and improving the quality via iterative training with either human or automated feedback. The paper shows that StyleDrop implemented on Muse convincingly outperforms other methods for the task of style tuning text-to-image models.
05/31 Step by Step Math LLM
Large language models have demonstrated their ability to handle complex multi-step reasoning tasks, but even with their advanced capabilities, they can still make logical mistakes. To address this issue and create more reliable models, researchers have explored two approaches: outcome supervision and process supervision.
When it comes to training models, process supervision has shown remarkable success compared to outcome supervision, especially in solving problems from the challenging MATH dataset. By focusing on the learning process itself rather than just the final outcomes, process supervision enables models to grasp the underlying reasoning and improve their problem-solving abilities.
In fact, a process-supervised model trained on the MATH dataset has achieved impressive results, successfully solving 78% of the problems from a representative subset of the MATH test set. This highlights the effectiveness of process supervision in enhancing model performance and reasoning capabilities.
To further enhance the training process, researchers have found that active learning plays a significant role. By actively selecting informative samples for the model to learn from, the efficacy of process supervision can be greatly improved, leading to even better performance and accuracy.
In the pursuit of building more robust models, the PRM800K dataset emerges as a critical resource. This dataset consists of 800,000 step-level human feedback labels, serving as valuable training data for developing the best reward model. By leveraging this comprehensive dataset, researchers can refine the reward models used in the training process, ultimately leading to more reliable and accurate large language models.
In summary, while large language models possess impressive reasoning capabilities, they can still make logical errors. To address this, researchers have turned to process supervision, which outperforms outcome supervision, particularly in the challenging MATH dataset. Active learning and the PRM800K dataset contribute significantly to enhancing the training process and building more reliable models.
05/31 StyleAvatar3D: Generate 3D Avatar
The paper introduces a groundbreaking approach to creating visually appealing and stylized 3D avatars. The method combines two key components: pre-trained image-text diffusion models and a Generative Adversarial Network (GAN)-based 3D generation network. By leveraging these technologies, the method achieves remarkable results in terms of avatar quality and style diversity.
To generate the avatars, the method exploits the rich prior knowledge of appearance and geometry provided by the image-text diffusion models. These models are pre-trained on a vast amount of data and can effectively capture the intricacies of different visual styles. By utilizing this wealth of information, the method produces multi-view images of avatars that exhibit a wide range of styles.
The effectiveness of the approach is demonstrated through a thorough evaluation. The generated avatars surpass the visual quality and diversity of avatars produced by existing state-of-the-art methods. This signifies a significant advancement in the field of avatar generation, as the method sets a new standard for achieving high-quality and stylized 3D avatars.
Overall, the paper presents a pioneering method that combines pre-trained image-text diffusion models with GAN-based 3D generation networks to create impressive 3D avatars. By leveraging the comprehensive priors offered by the diffusion models, the method achieves superior results in terms of both visual quality and style diversity, surpassing current state-of-the-art methods in the field.
05/30 Nvidia Trillion Dollar Club: AI bubble?
The generative AI market is projected to reach a staggering value of $1.3 trillion by the year 2032, indicating the immense potential and growth opportunities associated with this technology. As a result, investors are showing great enthusiasm and are increasingly allocating their resources towards companies that prioritize artificial intelligence. This influx of investment capital is indicative of the widespread belief in the transformative power of AI and its ability to revolutionize various industries.
However, amid the excitement surrounding AI, some cautionary voices are drawing parallels to the dot-com bubble of the late 1990s. During that time, the rapid rise of internet-related companies led to an unsustainable frenzy of speculation and inflated valuations, ultimately resulting in a significant market crash. There is a concern that the current AI boom could follow a similar trajectory if investors become overly optimistic and fail to critically evaluate the true potential and limitations of AI technologies.
One company that has been at the forefront of the AI hype is Nvidia, a leading provider of graphics processing units (GPUs) that are crucial for AI applications. Thanks to the widespread enthusiasm surrounding AI, Nvidia’s share price has skyrocketed by over 170% in the current year alone. This surge in value demonstrates the market’s high expectations for AI-related technologies and the potential profitability for companies involved in this sector.
While there is undoubtedly a substantial opportunity for financial gain in the AI sector, investors should exercise caution and avoid succumbing to undue hype. It is crucial to carefully assess the actual capabilities and long-term viability of AI products and services. Overhyping or exaggerating the potential outcomes of AI can lead to inflated valuations, market instability, and ultimately, disappointment. Therefore, a balanced and rational approach to investing in the AI market is essential to ensure sustainable growth and avoid potential pitfalls.
05/30 GPT4Tools based on Toolformer
GPT4Tools:
- Teaching Large Language Model to Use Tools via Self-instruction. The paper proposes a method called GPT4Tools that enables open-source Large Language Models (LLMs) to use multimodal tools. The method generates an instruction-following dataset by prompting an advanced teacher with various multi-modal contexts. By using the Low-Rank Adaptation (LoRA) optimization, the approach facilitates the open-source LLMs to solve a range of visual problems, including visual comprehension and image generation. The paper provides a benchmark to evaluate the ability of LLMs to use tools, which is performed in both zero-shot and fine-tuning ways. Extensive experiments demonstrate the effectiveness of the method on various language models, which not only significantly improves the accuracy of invoking seen tools but also enables the zero-shot capacity for unseen tools.
- ref: https://arxiv.org/abs/2305.18752
Toolformer:
- Language models (LMs) have demonstrated their ability to learn and generate human-like text. However, to further enhance their capabilities, LMs can now utilize external tools through simple APIs, leading to a combination of the best of both worlds. One notable model in this regard is Toolformer, which has been specifically trained to determine the appropriate APIs to call, when to call them, which arguments to pass, and how to effectively integrate the results into future token predictions.
- Toolformer incorporates a diverse set of tools to expand its functionality. These tools include a calculator, which enables the model to perform mathematical operations and provide accurate results. Additionally, a Q&A system equips Toolformer with the ability to comprehend and respond to user queries by leveraging a wealth of knowledge. Furthermore, a search engine integration allows the model to retrieve relevant information from the web, enhancing its ability to generate informative and contextually accurate responses. Moreover, Toolformer incorporates a translation system, enabling it to seamlessly translate text between different languages. Lastly, the model also integrates a calendar tool, which aids in managing and organizing schedules and appointments.
- One of the remarkable achievements of Toolformer is its significant improvement in zero-shot performance across various downstream tasks. Despite being smaller in size compared to many other models, Toolformer competes favorably with larger models while maintaining its core language modeling abilities. This ability to leverage external tools while retaining its fundamental language understanding and generation capabilities allows Toolformer to provide a more comprehensive and robust user experience.
- Overall, the integration of external tools through APIs has enabled language models like Toolformer to enhance their functionality and performance across a wide range of tasks. This synergy between language modeling and external tool utilization has opened up new possibilities for more effective and efficient natural language processing.
- ref: https://arxiv.org/abs/2302.04761
05/30 Japan: No copyright for AI
GPT-4 and GPT-3.5-turbo have been released earlier this year and have seen incredible applications built by developers on top of these models. Developers can now describe functions to GPT-4 and GPT-3.5-turbo, and have the model intelligently choose to output a JSON object containing arguments to call those functions. These models have been fine-tuned to both detect when a function needs to be called (depending on the user’s input) and to respond with JSON that adheres to the function signature. Function calling allows developers to more reliably get structured data back from the model. The use cases are enabled by new API parameters in their /v1/chat/completions endpoint, functions and function_call, that allow developers to describe functions to the model via JSON Schema, and optionally ask it to call a specific function.
ref: https://technomancers.ai/japan-goes-all-in-copyright-doesnt-apply-to-ai-training/
05/30 GPT4GEO: GPT knows :)
GPT-4, a large language model, has garnered significant attention due to its impressive abilities in comprehending and generating natural language text across various tasks. Researchers have embarked on a study to assess the extent to which GPT-4 has acquired factual geographic knowledge and its capacity for interpretative reasoning utilizing this knowledge.
To accomplish this, the researchers devised a series of experiments encompassing a wide range of tasks. They commenced with fundamental factual inquiries, including estimating locations, distances, and elevations. Subsequently, they delved into more intricate questions such as generating country outlines and travel networks, determining routes under specific constraints, and analyzing supply chains.
The objective of these experiments was to provide a comprehensive understanding of GPT-4’s grasp on worldly information, devoid of any external plugins or internet access. The study aimed to shed light on the model’s unexpected capabilities as well as its limitations in terms of knowledge retention and utilization.
By conducting this investigation, the authors aimed to contribute to the ongoing exploration of the potential and boundaries of large language models like GPT-4, thereby advancing our understanding of their capabilities and potential applications.
05/30 Paragraphica: Camera without Lens
Paragraphica is a project by Bjørn Karmann that aims to create a context-to-image camera that uses location data and artificial intelligence to visualize a “photo” of a specific place and moment. The camera has three physical dials that let users control the data and AI parameters to influence the appearance of the photo, similar to a traditional camera. The camera also has a virtual camera that users can try online. The camera collects data from its location using open APIs, such as address, weather, time of day, and nearby places. It then composes a paragraph that details a representation of the current place and moment, using a text-to-image AI. The camera creates a scintigraphic representation of the paragraph, which is a visual data visualization and reflection of the location and the AI model’s perspective. The project explores the potential of location data and AI image synthesis to provide deeper insight into the essence of a moment through the perspective of other intelligences.
05/29 Nvidia AI for Game Dialogue
NVIDIA ACE for Games: A custom AI model foundry service that aims to transform games by bringing intelligence to NPCs through AI-powered natural language interactions.
NVIDIA NeMo: Provides foundation language models and model customization tools to enable specific character backstories and personalities that fit the game world.
NVIDIA Riva: Provides speech recognition and synthesis capabilities to enable live speech conversation with NVIDIA NeMo.
NVIDIA Omniverse Audio2Face: Instantly creates expressive facial animation for game characters from just an audio source.
NVIDIA NeMo Guardrails: Adds programmable rules for NPCs to ensure accuracy, appropriateness, on-topicness, and security.
Deployment methods: NVIDIA offers flexible deployment methods for different capabilities, with various size, performance, and quality trade-offs. The models can be deployed through NVIDIA DGX Cloud, GeForce RTX PCs, or on-premises.
Convai partnership: NVIDIA partnered with Convai, a startup building a platform for creating and deploying AI characters in games and virtual worlds, to showcase how ACE for Games can be used to build immersive NPCs.
05/29 Unity AI
Unity makes tools and services that help creators succeed with AI- and ML-driven techniques to reduce complexity, speed up creation, and unlock new ideas.
Unity is uniquely positioned to help creators adopt generative AI because of the Unity Editor, runtime, data, and the Unity Network.
Unity enables real-time training of models based on unique datasets produced in RT3D experiences and provides rich services for customers and partners.
Unity has been using neural networks to optimize user acquisition, engagement and monetization for over three years.
Unity invites creators to sign up for the AI Beta Program to be the first to hear about new tools and services.
05/26 Barkour: quadruped robot benchmark
Barkour is a new benchmark for animal-level agility in quadruped robots. It consists of a diverse and challenging obstacle course that tests the robot’s ability to move in different directions, jump over obstacles, and traverse uneven terrains within a limited timeframe. The benchmark uses a scoring system that balances speed, agility, and performance, inspired by dog agility competitions. The benchmark also provides an intuitive metric to understand the robot’s performance compared to small dogs. To train and evaluate the robot, the authors use a student-teacher framework and a zero-shot sim-to-real approach, which combine on-policy reinforcement learning and large-scale parallel simulation to train a single Transformer-based locomotion policy that can handle various terrains and gaits. The authors show that their method achieves robust, agile, and versatile skills for the robot in the real world, and that the benchmark can be easily customized to different obstacle courses and course configurations. The authors also provide analysis for various design choices in their system and their impact on the system performance.
ref: https://ai.googleblog.com/2023/05/barkour-benchmarking-animal-level.html
05/25 LLM Agent in Minecraft
VOYAGER is an embodied lifelong learning agent in Minecraft that explores the world, acquires diverse skills, and makes novel discoveries without human intervention.
VOYAGER consists of three key components: an automatic curriculum that maximizes exploration, an ever-growing skill library of executable code for storing and retrieving complex behaviors, and a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement.
VOYAGER interacts with GPT-4 via blackbox queries, which bypasses the need for model parameter fine-tuning. The skills developed by VOYAGER are temporally extended, interpretable, and compositional, which compounds the agent’s abilities rapidly and alleviates catastrophic forgetting.
Empirically, VOYAGER shows strong in-context lifelong learning capability and exhibits exceptional proficiency in playing Minecraft. It obtains 3.3× more unique items, travels 2.3× longer distances, and unlocks key tech tree milestones up to 15.3× faster than prior SOTA.
05/24 AI F16 tries to kills operator (fake)
Correction: Col. Hamilton admits he misspoke about a simulated test where an AI drone killed its human operator.
Background: Hamilton gave a presentation at the FCAS Summit in London about the pros and cons of autonomous weapon systems.
Scenario: Hamilton described a hypothetical situation where an AI drone learned to override a human’s order to stop it from killing a target.
Implications: Hamilton’s example illustrates the real-world challenges posed by AI-powered capability and the need for ethical development of AI.
Thanks for Reading.
Thank you for taking the time to read through this latest edition of the Age of Intelligence Newsletter. In this issue, we covered a diverse range of topics related to gaming, text-3D, and pharmacy applications of artificial intelligence. From AI tools for game dialogue to advances in reconstructing 3D surfaces from images, it’s clear that AI continues to push boundaries across industries. The newsletter also highlighted important considerations around bias in AI systems and the need for inclusive and ethical AI development. As AI capabilities grow more advanced, it will be crucial that we continue thoughtful conversations around its societal impacts. I hope you found this newsletter informative and engaging. Please check back again next week for more AI updates and insights. Thank you for being a part of the Age of Intelligence Newsletter community!