Let's Dream
Table of Contents
Let’s explore the latest AI advances in medical AI, robotics, and more. Med-PaLM 2 achieves physician-level performance on medical question answering. RoboCat demonstrates versatile robotic manipulation skills acquired through self-improvement. We’ll also learn about using diffusion models for high-quality 3D rendering from text prompts, without 3D training data. On the policy front, the White House urges tech companies to address AI risks, while analysis shows current models do not fully comply with proposed EU regulations.
Articles #
07/12 New Google Bard
Bard is now available in over 40 languages, including Arabic, Chinese, German, Hindi, and Spanish. It has also expanded to more countries like Brazil and across Europe.
New features allow you to listen to Bard’s responses out loud in over 40 languages. You can also adjust the tone and style of responses to be simple, long, short, professional or casual. This is currently in English and expanding.
You can now pin and rename conversations with Bard to revisit prompts later. This is in over 40 languages.
Python code generated by Bard can now be exported to Replit in addition to Google Colab. Available in over 40 languages.
You can share parts or all of your Bard chat conversations via shareable links. Live in over 40 languages.
Images can now be included in prompts to have Bard analyze them and incorporate into responses. Currently in English, expanding to more languages.
Overall, Bard is expanding globally with more languages, countries, customization features, productivity features, and visual capabilities through Google Lens integration. Goal is to boost creativity, productivity and idea generation.
ref: https://blog.google/products/bard/google-bard-new-features-update-july-2023/
07/11 Anthropic's Claude 2 AI
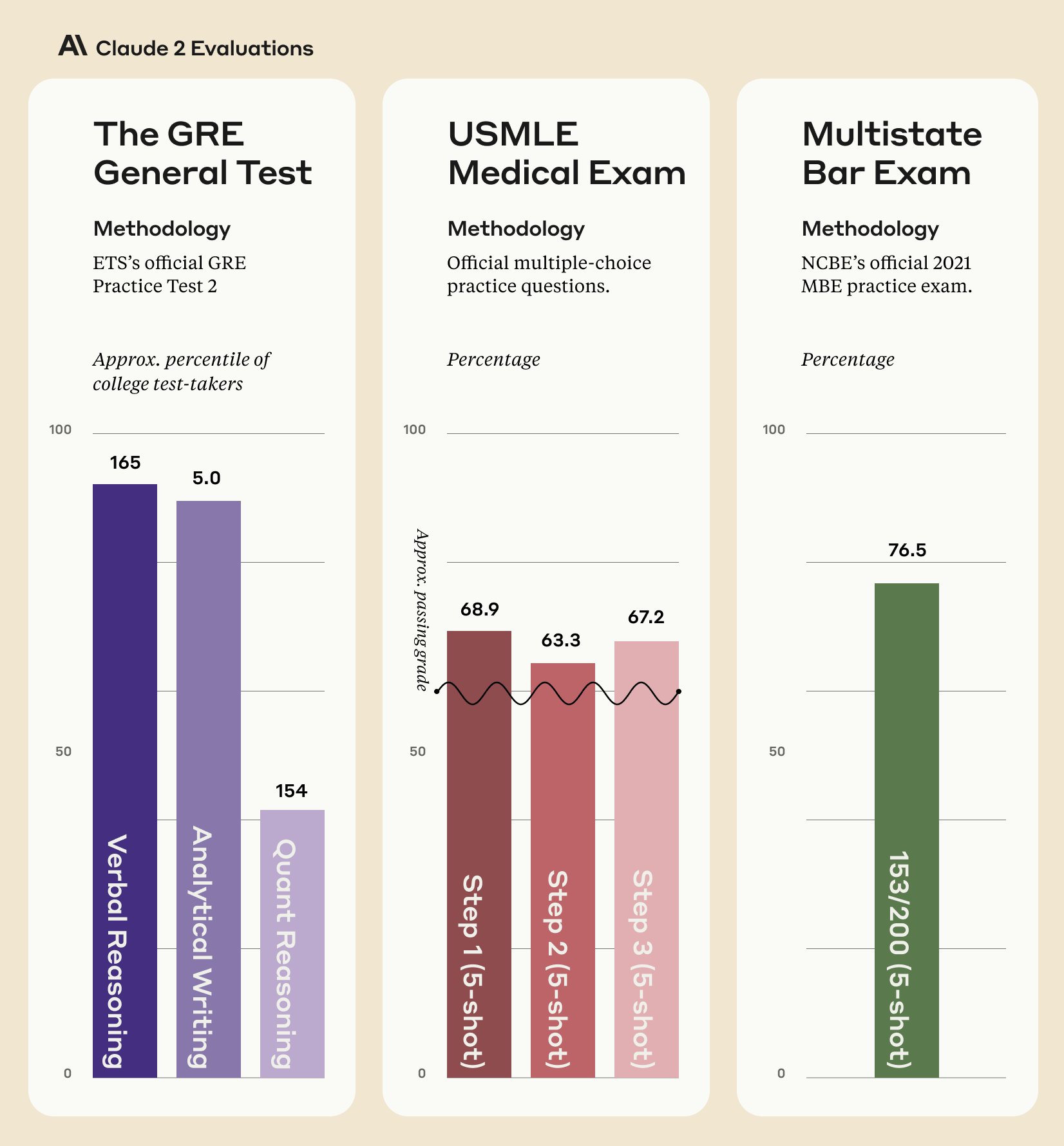
Claude 2 is Anthropic’s new AI assistant model.
It has improved performance, longer responses, and can be accessed via API or new public beta website.
Improvements in coding, math, reasoning skills (e.g. 76.5% on Bar exam multiple choice vs 73% for Claude 1.3).
Scores above 90th percentile on GRE reading/writing and median on quantitative reasoning compared to graduate school applicants.
Claude 2 API pricing unchanged from Claude 1.3.
Beta website allows anyone in US and UK to try conversing with Claude.
Increased maximum input/output length - can process documents up to 100K tokens, and generate responses up to a few thousand tokens.
Greatly improved coding ability (71.2% on Codex HumanEval vs 56% for previous version).
Improved grade-school math score (88% on GSM8k vs 85.2% previously).
Improved safety - 2x better at giving harmless responses, though no model is completely immune from misuse.
07/06 SQL Copilot

Introduces NSQL, a new open-source family of foundation models for SQL generation. Includes models of sizes 350M, 2B, and 6B parameters.
NSQL is designed to address challenges with using foundation models in enterprise: lack of personalization, quality issues on complex SQL, and privacy/deployment constraints.
NSQL uses a two-phase training approach:
Pretrain on large corpus of general SQL code (unsupervised).
- Finetune on text-to-SQL dataset with schema and instructions (supervised).
- Curated text-to-SQL dataset from over 20 public sources, with 290k examples after processing.
NSQL 6B outperforms all existing open source models on Spider and GeoQuery benchmarks, approaching performance of closed models like ChatGPT.
Detailed experiments show instruction tuning leads to significant gains over just pretrained models.
Qualitative analysis shows NSQL follows instructions better than general code models, with less hallucination.
Failure cases include complex nested SQL and need for explicit instructions on business logic.
Future work could improve NSQL via better training data, textbooks, and enterprise customization.
Overall, NSQL provides a strong starting point for organizations to build customized enterprise foundation models to enhance analytics productivity.
ref: https://www.numbersstation.ai/post/introducing-nsql-open-source-sql-copilot-foundation-models
07/05 OpenAI team for Superalignment
OpenAI is launching a new team focused on solving the problem of superintelligence alignment within 4 years.
Superintelligence alignment refers to ensuring AI systems much smarter than humans still follow human intent and values.
Current techniques for AI alignment rely on human oversight, but these will not work for superintelligent AI that surpasses human capabilities. New technical breakthroughs are needed.
The new “Superalignment” team will be co-led by Ilya Sutskever and Jan Leike.
20% of OpenAI’s secured compute over the next 4 years will be dedicated to this effort.
The team will focus on 3 areas:
- Developing scalable training methods using AI oversight
- Validating alignment through testing for problematic behavior and internals
- Stress testing the entire pipeline by deliberately training misaligned models
They are looking for top ML researchers and engineers to join the effort.
Solving superintelligence alignment is viewed as critical to achieve OpenAI’s mission. The fruits of this work will be shared broadly.
This effort is in addition to existing work at OpenAI on improving safety of current models and mitigating other AI risks.
Superintelligence alignment is seen as one of the most important unsolved problems in ML. OpenAI believes focused effort by top researchers can solve it within 4 years.
07/04 Cuneiform Tablet Translation AI
Hundreds of thousands of cuneiform tablets have been unearthed, but many remain untranslated due to the time-intensive process and small number of qualified experts.
Cuneiform was the writing system used for ancient Akkadian, an extinct early Semitic language spoken in Mesopotamia.
A new AI translation model was developed that can translate Akkadian cuneiform quickly and accurately.
The model was trained on samples of transliterated texts and Unicode representations of cuneiform.
In tests, the AI model scored above the target baseline for quality translations.
The model handled nuances of different text genres well. It worked best on shorter, more formulaic texts.
The researchers aim to improve the model’s accuracy with more training data.
The goal is for the AI to act as an assistant to human experts, providing raw fast translations for scholars to refine.
This could help unlock the historic records in the hundreds of thousands of untranslated tablets and expand knowledge of ancient Mesopotamian history and culture.
ref: https://bigthink.com/the-future/ai-translates-cuneiform/
06/27 Baidu Erinie 3.5 > GPT-4
Baidu has released ERNIE 3.5, an upgraded version of their foundation model ERNIE.
ERNIE 3.5 powers the recently released ERNIE Bot v2.1.0, which was launched on June 21.
A key feature of ERNIE 3.5 is plugins like “Baidu Search” and “ChatFile” that expand its capabilities.
Compared to ERNIE 3.0, ERNIE 3.5 boosts inference throughput by 17x and training throughput by 2x.
In testing, ERNIE 3.5 surpassed ChatGPT 3.5 in comprehensive scores and outperformed GPT-4 in some Chinese language tasks.
ERNIE 3.5 has broad improvements in areas like creative writing, Q&A, reasoning, and code generation.
New techniques like Knowledge Snippet Enhancement improve ERNIE 3.5’s utilization of world knowledge.
ERNIE 3.5 reasoning abilities boosted in logic, math, and code through new data and methods.
ERNIE Bot v2.1.0 added new ChatFile plugin and math/writing improvements powered by ERNIE 3.5.
ERNIE Bot is already being used in applications like smart offices, marketing, education, finance, etc.
Baidu’s coding assistant Comate uses ERNIE Bot for natural language to code generation.
06/26 NemoAI: Simulating Life in Games
Scripting in video games allows for some basic simulation of life through pre-programmed interactions and choices, but does not scale well. Games like Mass Effect use extensive scripting for companion relationships.
The Sims was revolutionary in using AI systems like utility-based AI to have autonomous characters balance their own needs and make decisions. This allowed for emergent narratives. However, the characters still lacked deeper bonds.
Black & White used reinforcement learning to have creature companions learn based on player actions over time. This paved the way for modern deep learning techniques.
Recent advancements in AI like large language models create new opportunities for simulating life and relationships in games. Models can perceive and interpret game environments, form personalities and memories, take player input, and learn from experiences.
The prototype character Nemo demonstrates how modern AI can enable emergent scenarios based on perception, memory, personality traits, player actions, and real-time learning. Separating the character from the world also allows it to traverse new experiences.
Simulating life in games has commercial potential and ability to deepen engagement. Combining artistry and innovative technology will enable the next generation of immersive, interactive experiences.
06/26 Google Sheet AI with “Help me organize”
06/22 YouTube with AI-powered dubbing
06/21 Use 2FA and beware of scams
100k+ ChatGPT accounts have been leaked on the dark web, as reported by Group-IB.
— Rowan Cheung (@rowancheung) June 21, 2023
The majority (12,632) of the compromised credentials trace back to India, but users in many other countries were affected.
Protect yourself: Enable 2FA, and use different passwords. pic.twitter.com/pjGOTTx94c
06/21 Marvel Title sequence created by AI
06/20 New Turing Test for Chatbots
Alan Turing proposed the Turing test in 1950 to determine if a computer can think like a human by having evaluators conduct text conversations with a human and a machine.
Current AI chatbots like ChatGPT are getting very close to passing the traditional Turing test through fluid conversations.
Mustafa Suleyman, founder of DeepMind, argues the Turing test is no longer a meaningful measure of AI capabilities.
In his new book, Suleyman proposes replacing the Turing test with an “ACI or Artificial Capable Intelligence test” focused on goal-setting and task completion.
The Artificial Capable Intelligence test would give an AI system $100,000 to turn into $1 million by researching a business opportunity, making a product, and selling it online.
Suleyman expects AI to pass this practical test in the next 2 years with major economic consequences.
The article summarizes Suleyman’s book about the transformative impact of advancing AI technology on society.
Suleyman will speak at the Bloomberg Technology Summit about regulating AI and practical ways forward.
06/20 White House Pushes Tech C.E.O.s to Limit Risks of A.I.
quote: “Hours before the meeting, the White House announced that the National Science Foundation plans to spend $140 million on new research centers devoted to A.I. The administration also pledged to release draft guidelines for government agencies to ensure that their use of A.I. safeguards “the American people’s rights and safety,” adding that several A.I. companies had agreed to make their products available for scrutiny in August at a cybersecurity conference.”
ref: https://www.politico.com/news/2023/06/20/biden-ai-regulatory-strategy-00102753
ref: https://www.washingtonpost.com/politics/2023/06/20/lawmakers-propose-blue-ribbon-ai-commission/
ref: https://www.nytimes.com/2023/05/04/technology/us-ai-research-regulation.html
06/16 Free Windows 10 Pro keys from ChatGPT

06/15 Foundation Model Compliance with Draft EU AI Act

The paper evaluates whether major foundation model providers like OpenAI and Google comply with draft requirements in the EU’s proposed AI Act.
The authors identify and categorize 22 requirements for foundation model providers in the AI Act draft adopted by the EU Parliament. They select 12 requirements to assess that can be evaluated with public information.
The 12 requirements relate to disclosure of data resources, compute resources, model characteristics, and deployment practices. Many center on transparency.
The authors design 5-point rubrics to assess compliance with the 12 requirements and score 10 major foundation model providers.
Compliance is uneven across providers. Many score poorly on disclosing copyrighted training data, compute/energy use, risk mitigation, and evaluation/testing.
Open source models tend to score higher on resource disclosure but lower on deployment monitoring. Closed models show the opposite pattern.
No provider fully complies, but the scores indicate it is feasible for providers to substantially improve compliance. Compliance has decreased in recent major model releases.
Key recommendations are to prioritize transparency, clarify copyright issues, specify unclear parts of the Act like evaluation disclosure, and create standards.
06/14 Virtual Try-On clothes with Diffusion AI Models
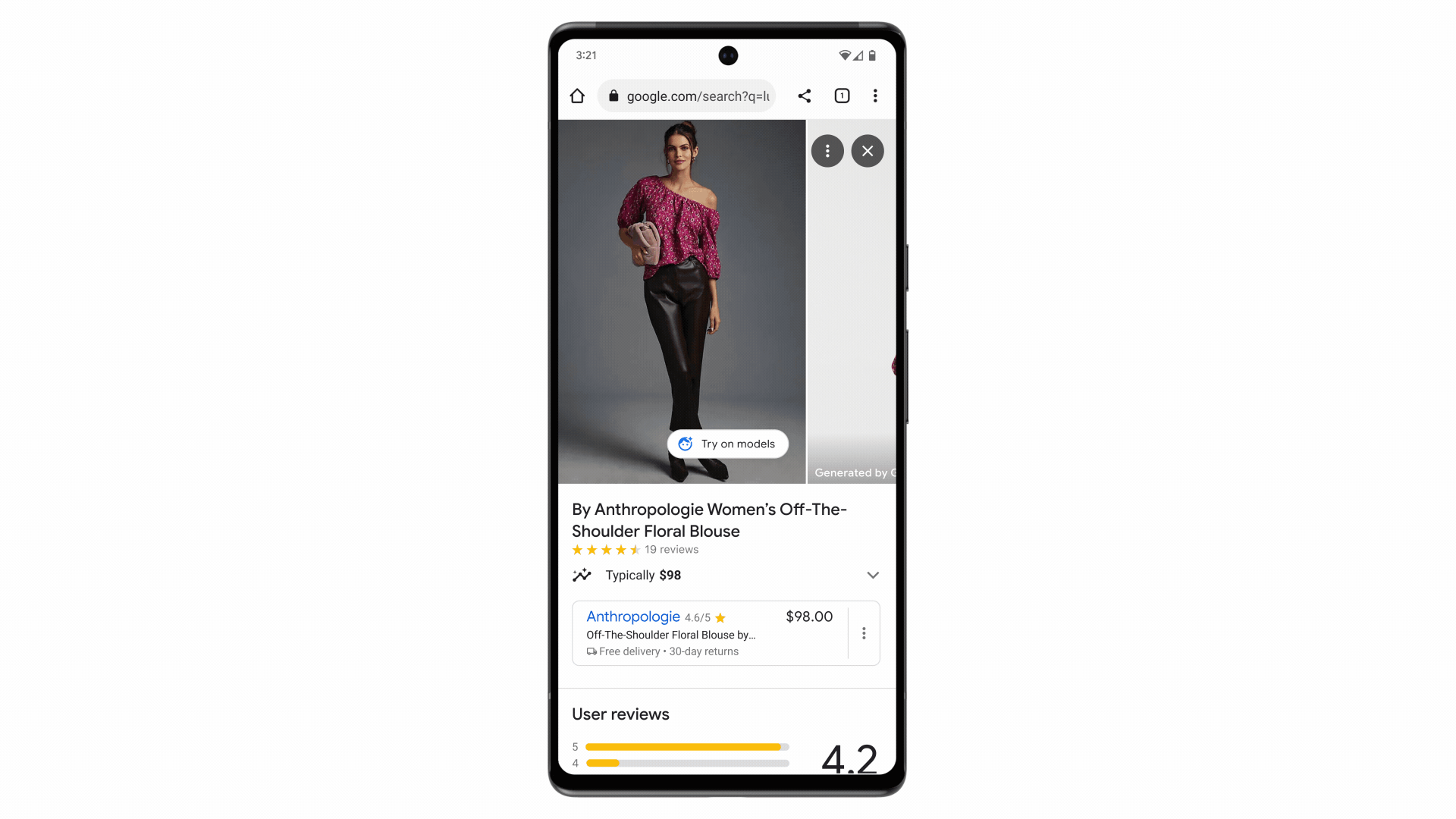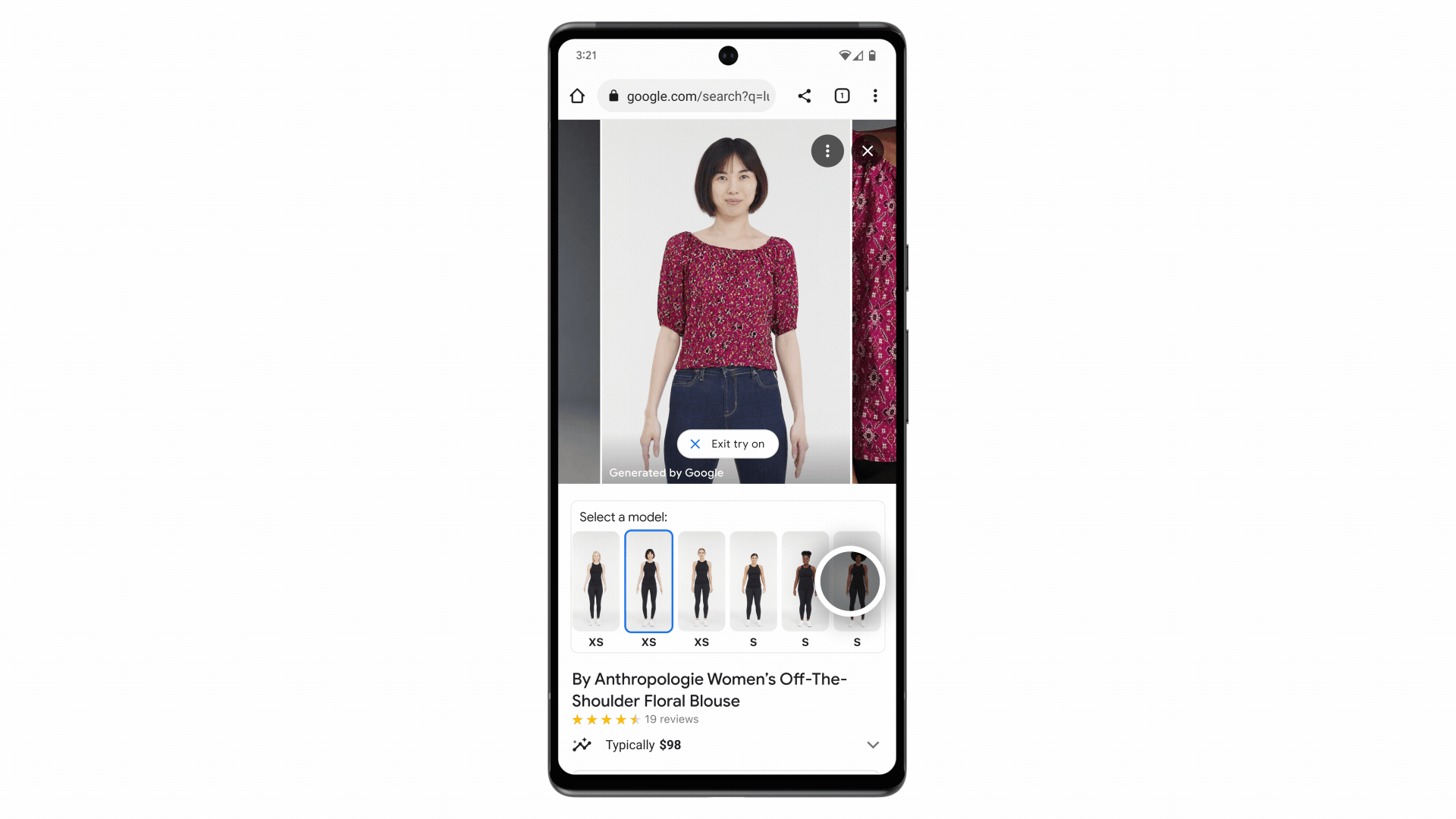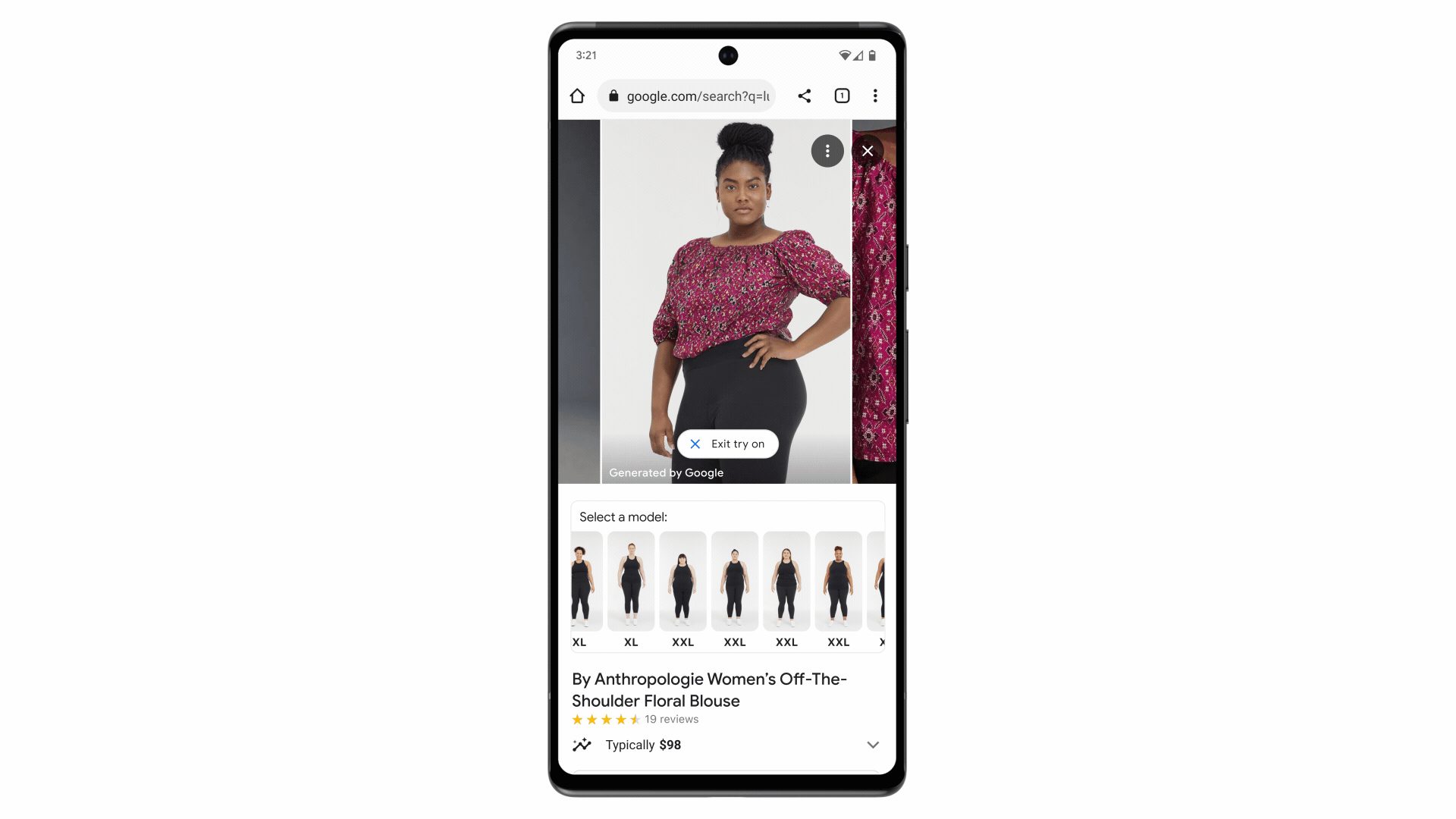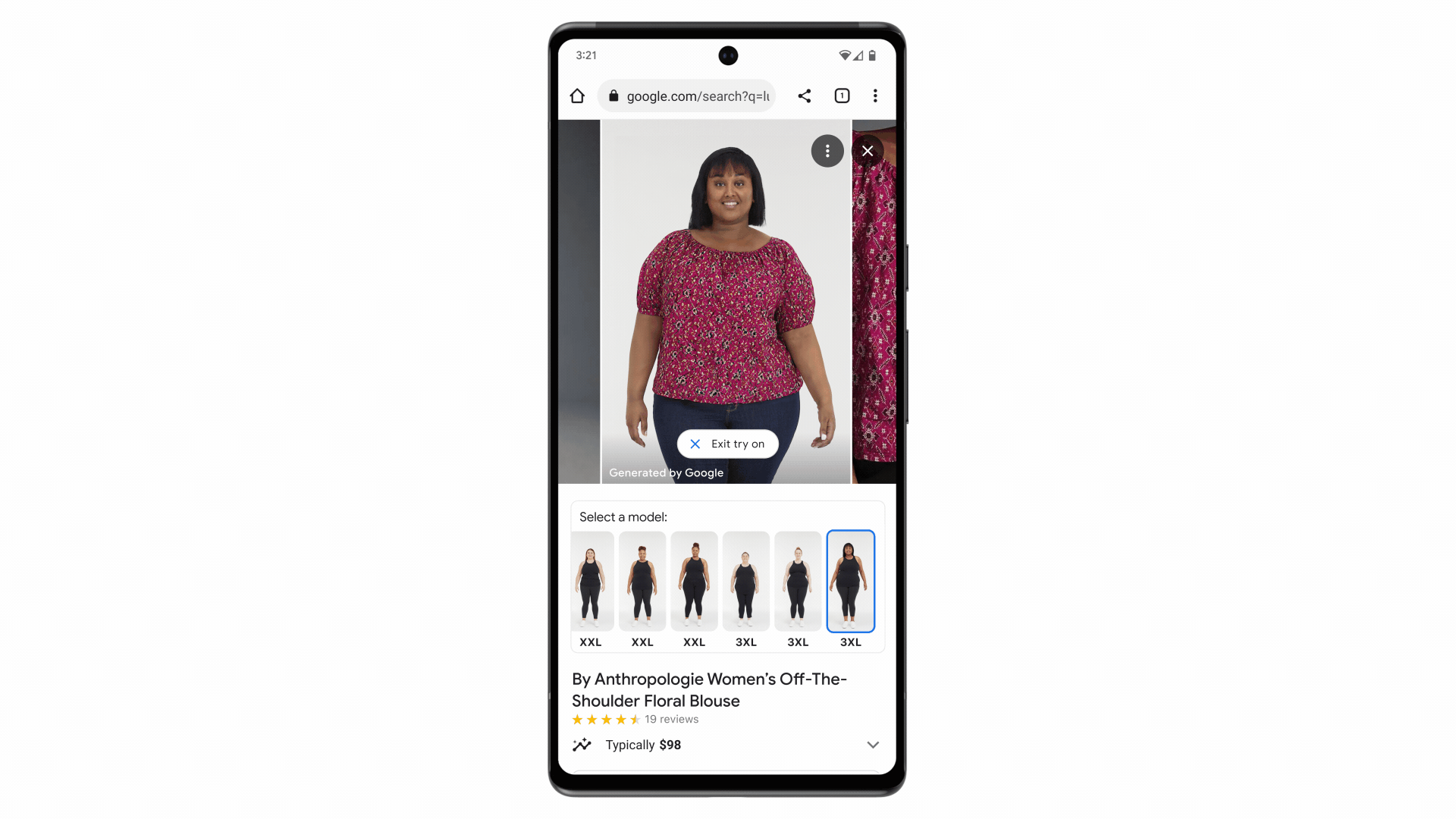

Google has developed a new generative AI model for virtual try-on that shows realistic images of clothes on different body types and poses.
The model uses a technique called diffusion, which gradually adds noise to an image and then removes it to reconstruct a high quality image.
Instead of text prompts, it takes two images as input - a clothing image and a person image - and uses cross-attention between two neural networks to generate the output image.
The model was trained on millions of image pairs from Google’s Shopping Graph dataset to learn how to match clothes to different bodies.
This allows the model to generate realistic images of clothes draping, folding, stretching, etc. on different models from various angles.
The new virtual try-on feature is launched for women’s tops from brands like Anthropologie, LOFT, H&M, and Everlane.
Over time it will expand to more brands and categories and become even more precise at generating realistic images.
The feature helps shoppers visualize how clothes will look on different body types before purchasing.
It aims to reduce returns from incorrect sizing/fit and improve the overall shopping experience.
ref: https://blog.google/products/shopping/virtual-try-on-google-generative-ai/
Research Papers #
Proton Model WRONG? Charm of Proton [3σ]
The theory of quantum chromodynamics (QCD) describes the proton as composed of quarks and gluons. In addition to the valence up and down quarks, there are infinite quark-antiquark pairs predicted.
Heavy quarks like charm can exist inside the proton either from high-energy collisions (perturbative QCD radiation) or as intrinsic components of the proton wavefunction (non-perturbative dynamics).
The existence of intrinsic heavy quarks, especially charm, in the proton has been hypothesized and debated for over 40 years. Previous efforts to conclusively establish intrinsic charm have been inconclusive.
This paper provides evidence for intrinsic charm quarks in the proton using a high-precision determination of the proton’s quark and gluon content based on machine learning and a large experimental dataset.
The 4-flavor number scheme (4FNS) charm quark PDF, which includes both intrinsic and perturbative components, is determined. This is transformed to the 3FNS charm PDF, which is purely intrinsic charm.
At large x ~ 0.4, the 3FNS charm PDF is significantly nonzero, peaking in a valence-like structure. This shape agrees with model predictions for intrinsic charm.
At small x < 0.2, the 3FNS charm PDF is consistent with zero once uncertainties are included. The intrinsic charm significance is ~2.5 sigma in the peak region.
Independent supporting evidence comes from recent LHCb measurements of Z bosons + charm jets, which agree with predictions using intrinsic charm but undershoot without it.
Inclusion of the LHCb data or earlier deep inelastic scattering charm data leaves the intrinsic charm unchanged while reducing uncertainties.
Combining all data gives >3 sigma local significance for intrinsic charm at large x, closing a longstanding question about the proton’s structure.
Med-PaLM 2: Medical LLM

Recent AI systems like large language models (LLMs) have shown impressive capabilities in medical question answering, including achieving high scores on benchmarks like MedQA.
However, prior work indicated room for improvement compared to actual physician answers, motivating more comprehensive evaluation.
The authors present Med-PaLM 2, a new medical LLM incorporating base model improvements and medical finetuning.
Med-PaLM 2 reaches 86.5% accuracy on MedQA, improving 19% over prior Med-PaLM model. It also exceeds or approaches state-of-the-art on other medical QA benchmarks.
The authors introduce a novel prompting strategy called ensemble refinement to improve reasoning in LLMs.
They evaluate Med-PaLM 2 using physician and layperson assessments of long-form answers to consumer medical questions.
In pairwise rankings, Med-PaLM 2 answers were preferred over physician answers on 8 of 9 clinically relevant criteria.
Two new adversarial question sets were introduced to probe model limitations. Med-PaLM 2 also showed significant gains over Med-PaLM on these questions.
Results indicate rapid progress towards physician-level QA abilities, but further validation on real-world use cases is still needed.
Careful evaluation and refinement of medical LLMs will be important to ensure positive impact on medicine and healthcare.
In summary, this work demonstrates strong gains in medical question answering abilities with the new Med-PaLM 2 model, while highlighting the importance of multi-dimensional human evaluation to fully assess these AI systems. The results represent an advance towards expert-level performance, but further research and validation is still required for real-world application.
Text-to-3D Rendering with Diffusion Models
The paper proposes a method to generate 3D models from text prompts using pretrained 2D image diffusion models, without needing any 3D training data.
Generative image models like diffusion models have made great progress in high-fidelity text-to-image synthesis, but adapting them to 3D requires large 3D datasets and efficient 3D architectures.
The paper introduces a loss based on probability density distillation that allows using a pretrained 2D diffusion model as a prior for optimizing a parametric 3D image generator (Neural Radiance Field or NeRF).
This DeepDream-like procedure optimizes a randomly initialized NeRF via gradient descent so its 2D renderings from random views match the diffusion model distribution.
The resulting 3D model can be viewed from any angle, relit, or composited into 3D scenes, using only a frozen 2D diffusion model as a prior.
Key components:
- Score Distillation Sampling (SDS) method to enable sampling via optimization in differentiable image parameterizations using diffusion models.
- Custom NeRF model tailored for text-to-3D generation.
- Loss minimizes KL divergence between diffusion model score functions and a Gaussian distribution based on the NeRF renderings.
The approach requires no 3D training data and no modification to the 2D diffusion model.
Results show high-quality coherent 3D objects generated from diverse text prompts.
06/30 Generating High-Quality Images from Brain EEG Signals

Proposes DreamDiffusion, a novel method to generate high-quality images directly from EEG brain signals, without needing to translate thoughts into text first.
Leverages powerful pre-trained text-to-image diffusion models like Stable Diffusion for image generation.
Uses temporal masked signal modeling on large EEG datasets to pre-train an EEG encoder to extract robust and effective representations. Randomly masks EEG signal in time domain and reconstructs.
Fine-tunes the pre-trained EEG encoder and Stable Diffusion model on limited EEG-image pairs.
Further aligns EEG, text, and image spaces using CLIP image encoder supervision to bring EEG embeddings closer to CLIP image embeddings.
Overcomes challenges of using noisy, limited, and individually variable EEG data for image generation.
Achieves promising qualitative and quantitative results in generating images that match the EEG data well.
Represents a significant advance for portable, low-cost “thoughts-to-image” conversion with applications in neuroscience, psychology, and human-computer interaction.
Limitations include only coarse-grained category-level image generation demonstrated so far.
06/29 3D Mesh Generation from Single Images in 45 Seconds
The paper proposes a novel method called One-2-3-45 that can reconstruct a high-quality 360° textured 3D mesh from a single input image in just 45 seconds.
The method consists of three main components:
- Multi-view synthesis: Uses the Zero123 model to generate multi-view images given the input image and specified camera transformations.
- Pose estimation: Estimates the elevation angle of the input image to determine camera poses.
- 3D reconstruction: Feeds multi-view images to a reconstruction module based on SparseNeuS to generate the 3D mesh.
Existing optimization-based methods using neural radiance fields struggle with inconsistent multi-view predictions from Zero123.
The paper proposes a reconstruction module based on sparse volumes and SDF to handle inconsistent views. Key strategies:
- 2-stage view selection for local correspondences.
- Mixing ground truth and predicted views during training.
- Supervising with depth maps.
Elevation angle estimation is necessary to determine absolute camera poses. A module is proposed to choose the angle with minimum reprojection error.
Experiments show One-2-3-45 reconstructs higher quality 3D meshes much faster (45 secs) than existing approaches.
It generalizes to unseen objects well since reconstruction relies on local correspondences.
The method can be extended to text-to-3D by using a text-to-image model to generate the input image.
Limitations include failures when input view lacks information or has ambiguous structures.
06/29 Graph Denoising for Protein Folding Prediction
The paper proposes a graph denoising diffusion model called GRADE-IF for inverse protein folding. The goal is to generate diverse amino acid sequences that can fold into a given 3D protein backbone structure.
Inverse folding is framed as a graph node denoising problem, where amino acid types on the nodes are randomly corrupted and then gradually recovered based on the graph structure.
The model uses a roto-translation equivariant graph neural network to process the protein graph and make denoising predictions. This provides built-in rotational and translational invariance.
Amino acid replacement matrices like BLOSUM are incorporated to encode biologically meaningful priors during the diffusion process. This reduces the sampling space.
Secondary structure information is also provided as a condition to the model to further narrow down the sequence search space.
The proposed model achieves state-of-the-art recovery rates on benchmark datasets like CATH, improving by 4-5% over previous methods.
Generated sequences exhibit high diversity yet retain core structural features, with predicted structures almost identical to native proteins.
A discrete version of DDIM is adapted to accelerate the sampling process up to 100x faster while maintaining good recovery performance.
Overall, the graph diffusion approach shows strong potential for generating diverse and structurally sound protein sequences for given backbones. The priors and conditions provide useful biases.
06/28 AttrPrompt: Generating Diverse Training Data

The paper investigates using large language models (LLMs) like ChatGPT as training data generators for text classification tasks.
It focuses on datasets with high cardinality (many classes) and diverse domains.
Existing works use simple class-conditional prompts to generate data, which can limit diversity and inherit LLM biases.
This paper proposes attributed prompts (AttrPrompt) that combine diverse attributes (e.g. location, length, style) randomly to generate more varied and attributed data.
The attributes and values are identified via an interactive process with ChatGPT.
Experiments on 4 datasets show AttrPrompt outperforms simple prompts, especially on high cardinality tasks.
Analysis shows simple prompts exhibit biases (e.g. regional bias) while AttrPrompt is more balanced.
Attribute diversity is shown to be important for model performance.
AttrPrompt achieves similar performance to simple prompts with only 5% of the querying budget.
Extends LLM data generation to multi-label classification and finds consistent improvements with AttrPrompt.
Overall, using diversely attributed prompts mitigates biases and improves diversity and efficiency of LLM-generated training data.
06/27 Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution
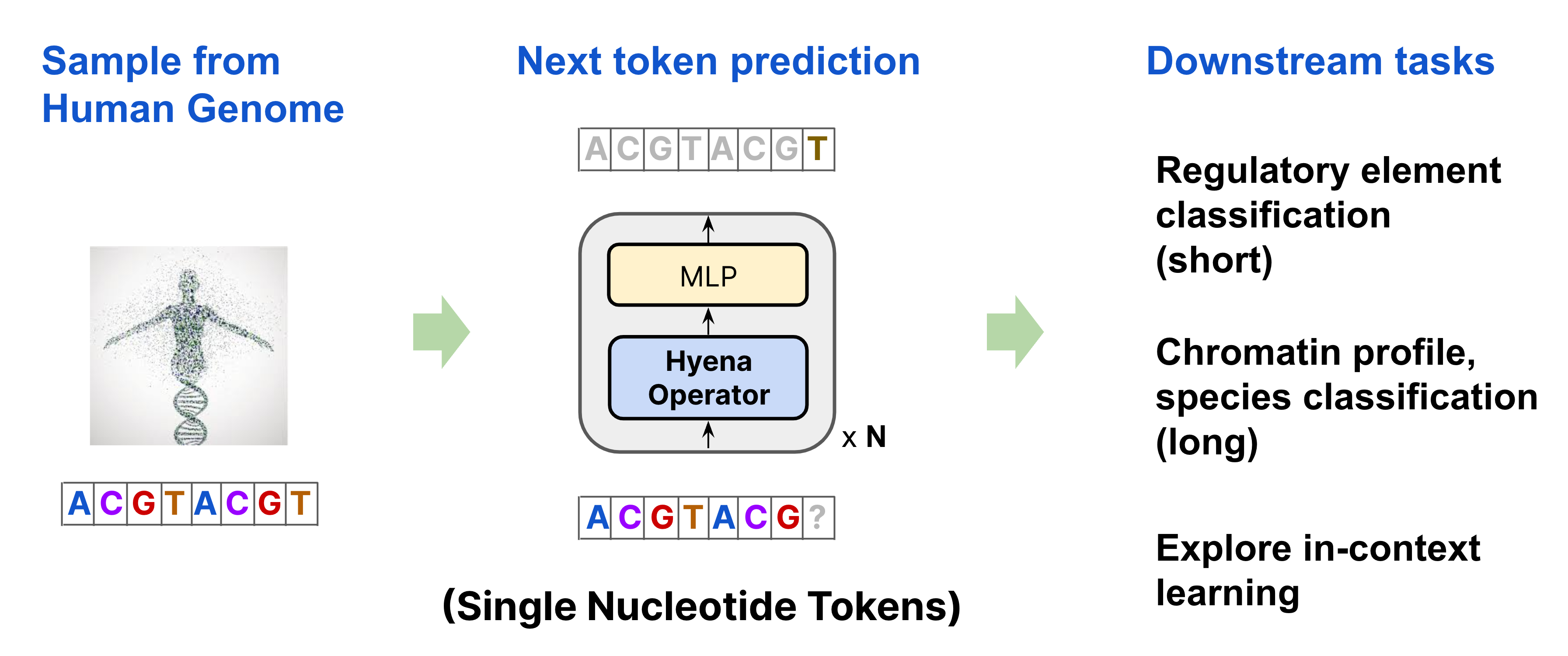
The paper introduces HyenaDNA, a new genomic foundation model for DNA sequence modeling. It is based on Hyena, a convolutional language model that allows longer context lengths compared to attention models.
HyenaDNA uses single nucleotide tokens, rather than k-mers or byte pair encodings used in previous models. This retains single nucleotide resolution critical for capturing mutations and SNPs.
HyenaDNA was pretrained on the human reference genome at context lengths up to 1 million nucleotides. This is 500x longer than previous dense attention-based models in genomics (512-4k tokens).
Training stability was improved using a sequence length warmup technique that gradually increases context length. This reduced training time by 40% and boosted accuracy.
On downstream tasks, HyenaDNA with 2.5B fewer parameters achieved state-of-the-art on 12/17 tasks from the Nucleotide Transformer benchmark.
On the GenomicBenchmarks, HyenaDNA exceeded the previous state-of-the-art by +9 accuracy points on average, and up to +20 points on enhancer identification.
HyenaDNA was 160x faster in training than Transformer attention at 1 million nucleotides due to more efficient convolutions.
The longer context enabled prompt tuning to adapt HyenaDNA to new tasks without updating pretrained weights.
On a 5-way species classification task using 450k contexts, HyenaDNA achieved over 99% accuracy where Transformer was infeasible to train.
Analysis of HyenaDNA’s embeddings showed improved clustering and prediction of gene biotypes compared to previous models.
ref: https://hazyresearch.stanford.edu/blog/2023-06-29-hyena-dna
06/27 LeanDojo: Theorem Proving with Retrieval-Augmented
The paper introduces LeanDojo, an open-source toolkit for learning-based theorem proving in Lean. It consists of data extraction tools, benchmarks, and models requiring only modest compute.
LeanDojo can extract training data from Lean code, including proof trees, tactics, and premise information. It also enables models to interact with Lean’s proof environment.
The paper constructs a new benchmark, LeanDojo Benchmark, with 96k theorems/proofs from Lean’s math library. It features a challenging split requiring generalization to novel premises.
The paper develops ReProver, the first retrieval-augmented language model for theorem proving. Given a proof state, it retrieves relevant premises and generates tactics conditioned on state + premises.
ReProver uses a Dense Passage Retriever augmented with two improvements: restricting retrieval to accessible premises and using in-file negatives.
Experiments show ReProver outperforms baselines without retrieval on LeanDojo Benchmark. It also evaluates well on existing datasets MiniF2F and ProofNet.
ReProver discovers 65 new Lean proofs for theorems without existing proofs. It facilitates research by releasing code/data/models without reliance on private resources.
Limitations include modest model size and lack of reinforcement learning. Future work may explore stronger models, different retrieval methods, and leveraging human interaction.
06/23 Natural Language Feedback for AI Systems
The paper proposes a framework to derive system-level natural language feedback from instance-level feedback. This allows aggregating feedback to make high-level improvements.
The framework has 4 main steps:
- Derive criteria from clustering and summarizing instance-level feedback.
- Use criteria to design prompts to refine bad examples.
- Use criteria for metric design to evaluate system changes.
- Fine-tune the model on good examples and refined examples.
They conduct case studies on improving query generation and response generation in dialog systems with this framework.
For query generation:
- Human feedback is clustered to derive criteria for good queries.
- Criteria are used in prompts to get GPT-3.5 to refine queries.
- Criteria also guide new metric design to evaluate query quality.
- Training on refined queries improves metrics.
For response generation:
- Similar process is followed to get criteria from feedback.
- New metrics designed based on criteria.
- Training on refined responses improves metrics.
Combining instance-level and system-level feedback brings further gains.
Human instance-level feedback results in more grounded refinements than GPT-3.5 feedback.
Overall, the paper demonstrates the effectiveness of using system-level natural language feedback derived from instances.
06/20 RoboCat: A self-improving robotic agent
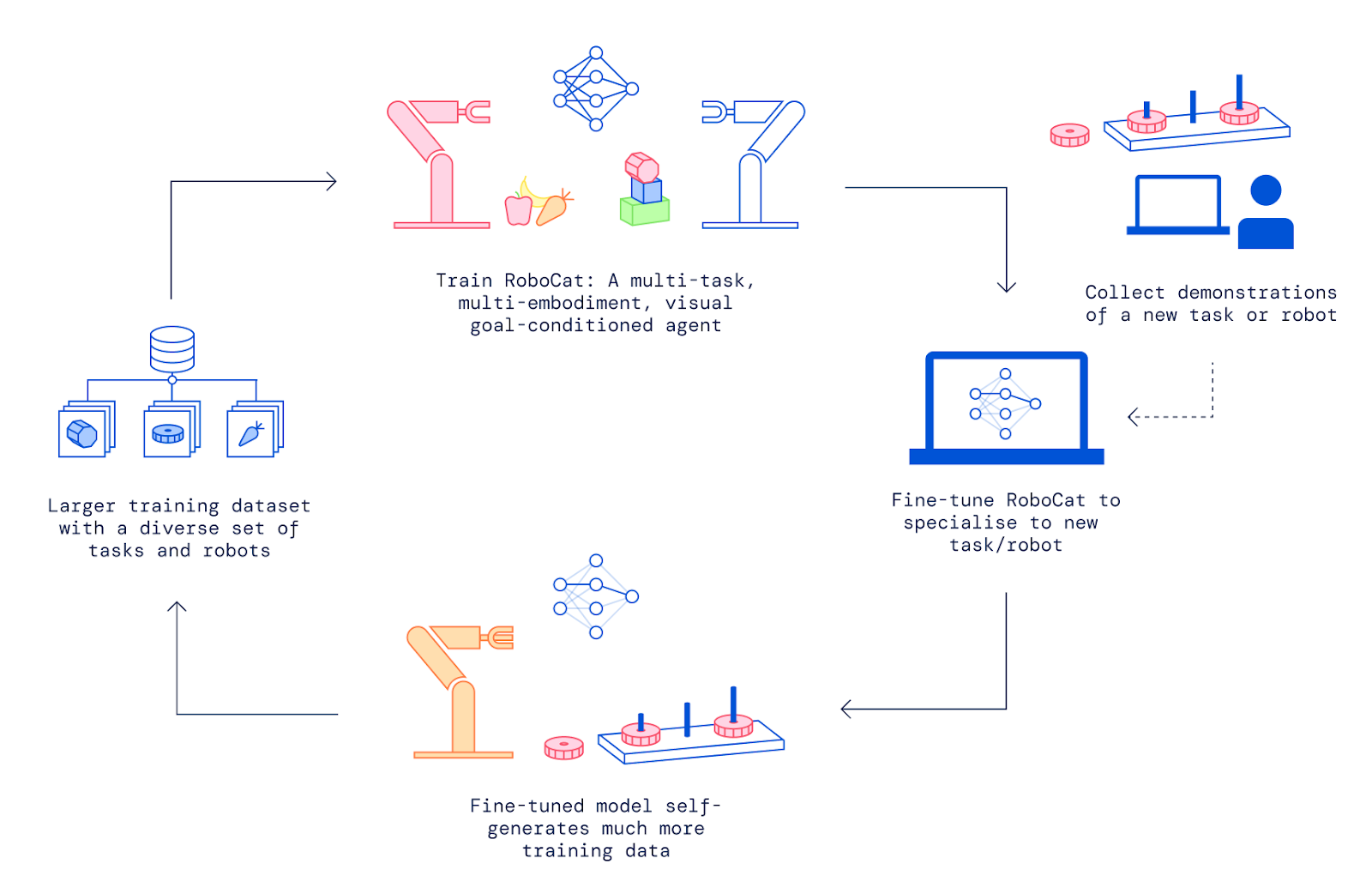
The paper introduces RoboCat, a transformer-based foundation agent for robotic manipulation. RoboCat is trained on a large and diverse dataset of manipulation tasks spanning multiple simulated and real robotic arms.
RoboCat can perform a wide variety of dexterous manipulation tasks in the real world when conditioned on goal images, including stacking, insertion, removal, and lifting tasks. It controls multiple real robot arms with different degrees of freedom and end effectors.
The agent is able to quickly adapt to new tasks and embodiments via fine-tuning on a small dataset of 100-1000 expert demonstrations. This allows efficiently acquiring new skills on real robots.
RoboCat incorporates a self-improvement loop - it uses fine-tuned policies to generate more data autonomously for a task, which is added to the training data for the next iteration of the generalist agent. This progressively improves the agent’s capabilities.
Experiments demonstrate that RoboCat can solve around 140 training task variations across multiple robot arms, object sets and task families. It also adapts via fine-tuning to 13 new downstream tasks.
RoboCat matches or exceeds the performance of prior state-of-the-art methods like BC-IMP and Gato on robotic manipulation benchmarks, while also demonstrating a broader range of capabilities.
Comparisons show RoboCat substantially outperforms single-task vision-based agents, highlighting the benefits of multi-task training. The self-improvement process also leads to better performance on training tasks and more efficient fine-tuning.
Analyses demonstrate RoboCat’s ability for cross-task transfer, adaptation with limited demonstrations, and embodiment generalisation. Scaling the diversity of training data improves RoboCat’s capabilities.
ref: https://www.deepmind.com/blog/robocat-a-self-improving-robotic-agent
06/20 Phi-1: Textbooks Are All You Need
The paper introduces phi-1, a new 1.3B parameter Transformer-based language model for code generation.
Phi-1 is trained on only 7B tokens of high quality “textbook” data, including filtered code from the web and synthetically generated textbooks and exercises.
Despite the small scale, phi-1 achieves state-of-the-art results on HumanEval (50.6% pass@1) and MBPP (55.5% pass@1).
The key idea is that higher quality, textbook-like data can dramatically improve learning efficiency and break existing scaling laws relating model size, dataset size, and performance.
The training data is designed to be clear, self-contained, instructive and balanced, unlike standard code datasets.
A base model phi-1-base is pretrained on “textbook” data. Finetuning on “textbook exercises” boosts performance significantly.
Emergent capabilities are shown after finetuning, like handling complex algorithms and external libraries not seen during finetuning.
Model size matters for emergence: phi-1 with 1.3B parameters shows more capabilities than 350M parameter phi-1-small.
The paper proposes unconventional problem evaluation using GPT-4 grading, confirming phi-1’s strong performance.
Contamination is studied by pruning “similar” exercises and retraining. Phi-1 still beats baselines after removing 40% of data.
Limitations include specialization for Python, lack of domain knowledge, and sensitivity to prompt variations or errors.
The work shows the importance of high quality data for training language models. Methodology for creating diverse, high-quality datasets is an important direction.
06/16 Voicebox: Multilingual Speech Generation
Voicebox is a versatile generative model for text-guided speech generation trained on a speech infilling task at large scale.
It uses a non-autoregressive flow-based model trained with flow matching on 60K hours of English audiobooks and 50K hours of multilingual audiobooks.
Voicebox can perform a variety of tasks like zero-shot TTS, speech denoising, content editing, and diverse speech sampling through in-context learning without task-specific training.
For English zero-shot TTS, Voicebox achieves state-of-the-art results, improving WER from 5.9% to 1.9% and similarity from 0.580 to 0.681 compared to VALL-E.
For cross-lingual zero-shot TTS across 6 languages, Voicebox reduces average WER from 10.9% (YourTTS) to 5.2% and improves similarity from 0.335 to 0.481 without using explicit speaker embeddings.
For transient noise removal, Voicebox outperforms Demucs and A3T with -8.8% WER, +0.450 similarity, and +0.80 mean opinion score improvements.
Voicebox can generate diverse and realistic speech. An ASR system trained solely on Voicebox data has only 0.4%/1.7% higher WER on Librispeech compared to training on real data, substantially better than prior TTS models.
Voicebox is up to 20 times faster than autoregressive models like VALL-E, and allows flexible trade-off between quality and speed.
ref: https://about.fb.com/news/2023/06/introducing-voicebox-ai-for-speech-generation/
ref: https://ai.meta.com/blog/voicebox-generative-ai-model-speech/
06/15 Inverse Scaling: When Bigger Isn’t Better
The paper investigates the phenomenon of inverse scaling, where language model (LM) performance on certain tasks gets worse as LM scale (size, data, compute) increases.
The authors ran a contest, the Inverse Scaling Prize, to collect examples of tasks exhibiting robust inverse scaling trends. They awarded prizes for 11 submitted tasks that showed clear inverse scaling across models.
Four hypothesized causes of inverse scaling were identified based on analysis of the submitted tasks:
- Strong Prior: LMs rely more on memorized sequences from pretraining rather than following in-context instructions.
- Unwanted Imitation: LMs imitate undesirable patterns from the training data.
- Distractor Task: LMs perform an easier, similar task instead of the intended harder task.
- Spurious Few-Shot: Misleading correlations in the few-shot examples cause the LM to consistently answer incorrectly.
The tasks helped reveal U-shaped scaling, where performance declines then improves again with scale. Some tasks showed inverted-U scaling, where performance first improves then declines.
Scaling trends were found to sometimes reverse multiple times, suggesting predictions of LM behavior require investigating emergent capabilities and phase changes.
Providing few-shot examples mitigated inverse scaling for some but not all tasks, showing instructions do not completely solve these issues.
The tasks aim to shed light on failures of current LMs to inform development of more reliable models. The data is released to enable further analysis of inverse scaling.
Overall, inverse scaling indicates that increased scale alone may not improve performance on all tasks, and more care is needed in LM training.
06/15 Infinigen: Procedural Generator of 3D scenes [not AI]
The paper introduces Infinigen, a procedural generator for photorealistic 3D scenes of the natural world.
Infinigen is entirely procedural - every asset, from shape to texture, is generated mathematically from scratch. This allows infinite variation and composition.
Infinigen focuses on generating objects and scenes from the natural world, including plants, animals, terrains, and natural phenomena.
Infinigen assets have real geometric detail, not just textures faking geometry. This ensures accurate ground truth data for tasks like 3D reconstruction.
Infinigen provides utilities to render synthetic images and extract common ground truth labels like depth, normals, optical flow, segmentation, etc.
Infinigen is built using Blender and contributions include a transpiler to convert node graphs to Python code and tools to automate simulations.
Infinigen contains 182 procedural asset generators with over 1000 tunable parameters covering a broad range of natural objects and scenes.
Experiments show Infinigen data helps train models that generalize to real images of natural scenes better than models trained on other synthetic datasets.
Infinigen is open source and free for anyone to use to generate unlimited assets and data.
In summary, Infinigen is a large-scale open-source procedural generator that can create unlimited photorealistic 3D data covering the natural world, to help advance computer vision research and applications. The key strengths are full procedural generation, photorealism, coverage of natural scenes, and easy access.
06/15 GPT4 Aces MIT Mathematics and EECS [Wrong]
The paper claimed that GPT-4 was able to achieve 100% accuracy on a test set of 288 questions from the MIT curriculum. However, upon examination of the test set, the analysis found several issues:
Approximately 4% of the test set contained unsolvable questions that did not provide enough information to answer properly. This calls into question how a 100% accuracy rate could be achieved.
The few-shot examples provided to the model as additional context for harder questions had high overlap and duplication with the original questions. In some cases, the few-shot examples contained the exact questions and answers, enabling the model to essentially “cheat.”
The code used for grading had issues - it checked the model’s answers against the ground truth solutions, re-prompting until the correct solution was reached. This binary feedback signal enables the model to guess the right answer through unlimited tries.
The code also had a parameter swap bug, feeding the question into the “system” prompt and the expert name into the “question” prompt. This resulted in improperly formed prompts.
The expert selection method produced incoherent expert prompts, splitting up sentences unnaturally as it tried to extract expert names.
The paper’s claims of verification through crowdsourced grading are questionable since the data issues call into question what was actually being verified.
Prior analysis of similar papers from the same group found issues with exaggerated claims of model abilities. This suggests systemic issues with the research methodology.
In summary, the key claims of the paper appear unsupported once the test set and grading methodology are examined in detail. The concerns raised call into question the validity of the reported 100% accuracy result. More rigorous verification is needed to substantiate such claims.
ref: https://www.notion.so/No-GPT4-can-t-ace-MIT-b27e6796ab5a48368127a98216c76864
06/15 Teaching Weaker AI Agents via Explanations
The paper explores whether large language models (LLMs) can act as teachers to improve the performance of weaker student LLMs on complex reasoning tasks.
It introduces a student-teacher framework to study this, where the teacher LLM can intervene and communicate explanations to guide the student LLM’s reasoning.
Communication is assumed to have an associated cost, so the teacher has a limited “intervention budget” for how many data points it can explain to the student.
The research questions explored are:
- Can a teacher LLM intervene to improve student LLM performance? (Yes, model teachers can be effective but not as good as human teachers).
- Given a budget, how should the teacher decide when to intervene? (Proposed an “expected utility” approach where the teacher simulates the student’s behavior to decide when an intervention would be most useful).
- Can the teacher use theory of mind to personalize explanations for a particular student? (Yes, prompting the teacher with examples of helpful explanations improves personalization).
- Do teacher explanations generalize to improve student performance on unexplained data in multi-turn interactions? (Yes, student accuracy improves on unexplained data).
- Can misaligned teachers intentionally lower student performance? (Yes, by misleading the student).
Overall, the work demonstrates LLMs can successfully teach weaker LLMs through personalized and generalizable explanations, highlighting their potential as reasoning teachers. But it also shows the risks if explanations are intentionally misleading.
06/15 Masked Diffusion Transformer

The paper proposes (MaskDiT), an efficient approach to train large transformer-based diffusion models by randomly masking a high proportion (e.g. 50%) of image patches during training.
An asymmetric encoder-decoder architecture is introduced where the transformer encoder operates only on unmasked patches and a lightweight decoder operates on the full set of patches.
The training objective consists of predicting the score of unmasked patches (denoising score matching loss) and reconstructing the masked patches (MSE loss). The reconstruction task provides global knowledge to prevent overfitting.
Experiments on ImageNet-256x256 show MaskDiT matches the performance of Diffusion Transformer (DiT) while only requiring 31% of its original training time.
With 50% masking, per-iteration training cost is reduced 2x. Larger batch sizes further improve efficiency.
Without guidance, MaskDiT achieves a Fréchet Inception Distance (FID) of 5.69, outperforming prior diffusion models.
With guidance, MaskDiT achieves a competitive FID of 2.28 compared to state-of-the-art while being much more efficient to train.
After masked training, a short unmasking tuning step is performed to close the distribution gap between training and inference.
Overall, the work enables efficient training of large diffusion models without sacrificing generative performance.
06/14 AssistGPT: Multi-Modal AI Assistant
- The paper proposes AssistGPT, a general multi-modal AI assistant system that can dynamically engage various tools to address complex visual tasks.
- AssistGPT consists of four core modules:
- Planner: Uses a large language model (e.g. GPT-4) to control the overall reasoning process. It plans the next step based on the current state.
- Executor: Executes external tools/APIs and returns feedback to the Planner.
- Inspector: Manages the input data and intermediate results to assist the Planner.
- Learner: Assesses system performance and records successful examples as in-context examples to improve.
- AssistGPT reasons in an interleaved language and code manner. The Planner plans in natural language, while structured code is used to invoke tools/models.
- The Inspector and structured code invocation allows efficient handling of complex inputs and intermediate results during reasoning.
- The Learner allows self-assessment of reasoning and collects successful trials as in-context examples to improve planning.
- AssistGPT integrates over 10 tools spanning functions like detection, grounding, captioning, QA, etc.
- It is evaluated on A-OKVQA and NExT-QA benchmarks, achieving strong performance.
- Qualitative examples demonstrate capabilities beyond benchmarks, like handling long videos, high-level queries, flexible inputs, etc.
- Main limitations are the lack of end-to-end module updating and the overhead of explaining tools to the Planner.
In summary, AssistGPT demonstrates how interleaved language-code reasoning and tool integration can enable multi-modal assistants to handle complex real-world queries. The core PEIL approach could be extended to diverse applications.
06/13 Rerender A Video
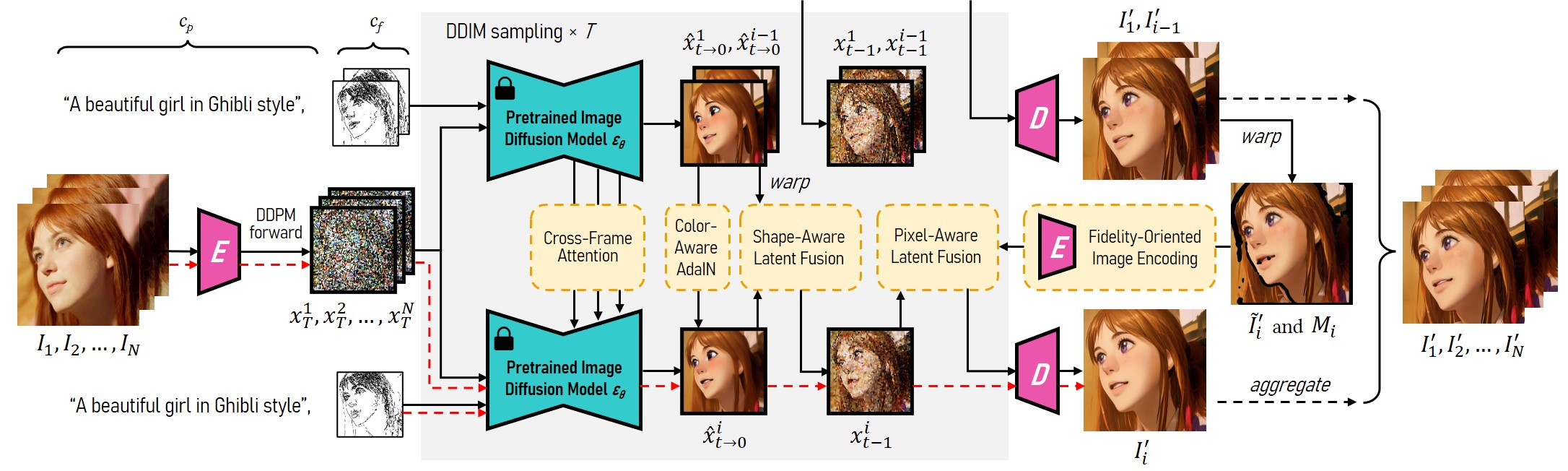
Key points from the paper “Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation”:
- Proposes a novel zero-shot framework to adapt image diffusion models for video-to-video translation guided by text prompts. The framework requires no training and is compatible with off-the-shelf image models.
- Consists of two parts: key frame translation and full video translation. Key frames are rendered by adapting image diffusion models with hierarchical cross-frame constraints for temporal consistency. Other frames are generated by propagating the key frames.
- Introduces cross-frame attention, shape-aware latent fusion, pixel-aware latent fusion and adaptive latent adjustment as hierarchical constraints at different diffusion sampling steps to achieve global style consistency and local consistency in shapes, textures and colors.
- Proposes fidelity-oriented image encoding to compensate for the distortions of the autoencoder and enable coherent latent feature warping. Also uses structure-guided inpainting for pixel-level fusion.
- Propagates rendered coherent key frames to other frames using temporal-aware patch matching and blending. This balances quality of diffusion models and efficiency of propagation.
- Achieves state-of-the-art results compared to existing zero-shot video translation methods in terms of temporal consistency, content-prompt alignment and overall quality.
- Framework is flexible in preserving input content and color by adjusting the noise level and allows compatible use of customized image models like DreamBooth and control methods like ControlNet.
- Limitations include reliance on optical flow estimation, trade-off between content and style, and uniform key frame sampling.
In summary, the paper proposes an effective zero-shot framework to adapt image diffusion models for coherent artistic video translation guided by text prompts, with innovations in hierarchical cross-frame constraints and fidelity-oriented encoding.
06/12 The AI Recursion: Model Collapse
Large language models (LLMs) trained on web data are susceptible to model collapse, where minority characteristics in the training data distribution are progressively lost. This leads to distorted generative outputs that do not match the true data distribution.
Model collapse is an irreversible defect where an LLM’s generated outputs contaminate its own training data. This causes a feedback loop that increasingly skews the model away from rare data cases.
Examples of model collapse include loss of diversity in generated text, blurred image details, and discrimination from dropping sensitive attributes like race or gender. The tails of the data distribution disappear.
Retaining a prestige copy of original human-authored data can help avoid model collapse. Introducing new, clean human-generated datasets into training is also important.
Fair representation of minority groups and rare data cases is essential in training data. More research is needed on techniques to sustain benefits of large-scale web scraping while preventing model collapse.
06/12 LLMs can label data as well as humans, but faster

LLMs can label text datasets at the same or better quality compared to skilled human annotators, but ~20x faster and ~7x cheaper.
For achieving the highest quality labels, GPT-4 is the best choice among out of the box LLMs (88.4% agreement with ground truth, compared to 86% for skilled human annotators).
For achieving the best tradeoff between label quality and cost, GPT-3.5-turbo, PaLM-2 and open source models like FLAN-T5-XXL are compelling.
Confidence based thresholding can be a very effective way to mitigate impact of hallucinations and ensure high label quality.
ref: https://www.refuel.ai/blog-posts/llm-labeling-technical-report
06/10 AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
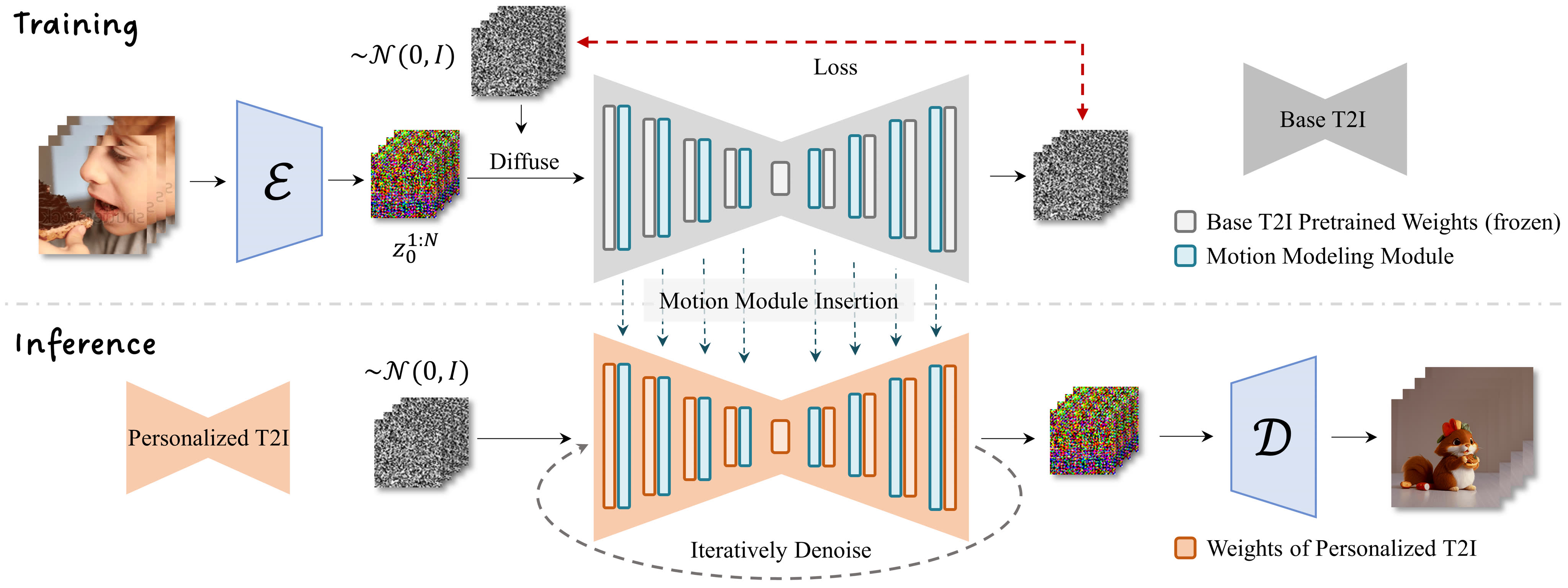
The paper proposes AnimateDiff, a framework to animate personalized text-to-image (T2I) models without model-specific tuning.
Once learned motion priors from large video datasets, AnimateDiff can animate most personalized T2I models derived from the same base model (e.g. Stable Diffusion).
The key idea is to train a separate motion modeling module on video data to distill motion priors. This module is then inserted into the frozen personalized T2I model at inference time.
The motion modeling module uses a simple temporal transformer design with self-attention blocks to enable information flow across frames.
Only the motion module parameters are updated during training, leaving the personalized T2I model unchanged to preserve its knowledge.
Once trained, the motion module can animate various personalized T2I models built on the same base model without further tuning.
Evaluated on anime, cartoon, and photographic personalized models. Shows smooth motions and animation while retaining domain diversity.
Compared to baseline method Text2Video-Zero. Achieves better temporal consistency and motion alignment.
Ablation on noise schedules shows tradeoff between visual quality and motion range. A schedule slightly different from T2I pre-training works best.
Limitation is difficulty animating highly stylized domains different from training data distribution. Future work could finetune on small in-domain videos.
Tools #
- Supertools: 100’s of AI tools.
- Pi: Hi, I’m Pi. I’m your personal AI, designed to be supportive, smart, and there for you anytime.
- transcriptdownload: Youtube transcript download and generation.
- playgroundai: Image Editing with AI.
- Stable Doodle: Sketch-to-image tool that converts a simple drawing into a dynamic image.
- qrcode-ai: AI-powered QR Code Generator.
- voice-cloning: Clone your own voice.
- beforesunset: AI-powered Planner.
- Veed AI Avatars: photorealistic and diverse AI Avatars.
- FlutterFlow AI: Build an app with AI.
- Interview AI: Mock interviews with AI.
- Brewnote: Note on Interviews.
- Submagic: AI-Powered Captions
Thanks for Reading.
This edition of the Age of Intelligence newsletter covered a diverse range of AI research advancements and news.
Key highlights include new models and capabilities in areas like speech synthesis (Meta’s Voicebox), image generation (text-to-3D rendering), robotics (DeepMind’s RoboCat), genomics (HyenaDNA), reasoning and knowledge (Anthropic’s Claude 2), SQL generation (NSQL), and theorem proving (LeanDojo).
Notable trends include leveraging textbooks and high-quality data for efficient training (Phi-1), analyzing the phenomenon of inverse scaling in LLMs, using hierarchical constraints for multi-modal generation (video translation), and frameworks for teaching weaker models (via explanations).
The newsletter also summarized policy developments around AI safety including new guidelines in the EU and U.S., and debates on appropriate evaluation of language model abilities.
Exciting real-world AI applications covered include virtual try-on powered by generative models, AI assistants for spreadsheets, and AI-generated video dubbing.
Finally, a list of additional AI tools across diverse use cases like content creation, productivity, etc. was provided.
Thank you for reading this edition and please look out for the next newsletter covering the latest in AI research and applications.