Dawn of Robots
Table of Contents
Let’s explore the latest AI advances in natural language processing, computer vision, robotics, and more based on recent research papers and announcements. This issue summarizes key highlights across generative models, vision transformers, multimodal systems, model evaluation techniques, and new datasets enabling geospatial, materials science, and graphics applications.
Articles #
Better Attention is All You Need
Deepfake speech
Scammers are using AI to mimic the voices of loved ones to exploit victims in increasingly sophisticated phone scams. They use “generative AI” to clone a person’s voice after collecting audio samples online.
Recent examples include scammers imitating a daughter’s voice, claiming kidnappers want ransom. Another involved using a cloned voice to pretend a car accident occurred and ask for money.
These “virtual kidnapping scams” are not new, but AI makes the voices more believable. Software can detect deepfakes via visual spectrograms, but average people can’t easily do this.
To protect yourself, be skeptical of sudden calls asking for money. Call the person back on their normal number or contact a family member to verify it’s really them. Also limit sharing personal info online that could help train AI voice cloning.
As AI capabilities grow, people need to become more cautious about assessing what voices and media they encounter to avoid being manipulated or scammed.
ref:
- (The Decoder) Deepfake speech is getting too good, fooling a quarter of listeners in study
- (CBS News) Phone scammers are using artificial intelligence to mimic voices
- (CBS News) Scammers use AI to mimic voices of loved ones in distress
- (The Conversation) AI scam calls imitating familiar voices are a growing problem – here’s how they work
- (USA Today) The call is coming from inside the internet: AI voice scams on the rise with cloning tech
Runway Gen-2: Text to Video
If you can imagine it, you can generate it.
— Runway (@runwayml) June 7, 2023
Gen-2 is now available on web and mobile: https://t.co/KctIodJz2t pic.twitter.com/tbo1t7JGeJ
Here’s a bonus cut of our new #Barbenheimer trailer. You can check out the full extended version over on YouTube. #barbiemovie #barbie #oppenheimer #movietrailer #AI #midjourney #trailer #margotrobbie #ryangosling #willfarrell #mattdamon pic.twitter.com/HgEuWHVPaZ
— Curious Refuge (@CuriousRefuge) July 19, 2023
TUTORIAL
— Tereza Havel (@terezahavel) July 26, 2023
Here's how I made a Barbie video using only Al.
Create your own in 7 easy steps!
Let's go! 🧵👇🏼#AiArt #BarbieMovie #Oppenheimer #RunwayML pic.twitter.com/leAGVV57Jz
🎬 Excited to share a little teaser trailer for my next @runwayml + MidJourney short film!
— Ammaar Reshi (@ammaar) July 31, 2023
Doctrine: brings a vivid dream I had years ago back to life using AI!
Three mysterious figures rule a secluded village, until a single, profound question threatens their reign.
- Story… pic.twitter.com/O8Jk9j1eTp
🎬 Trailer: Genesis (Midjourney + Runway)
— Nicolas Neubert (@iamneubert) July 26, 2023
We gave them everything.
Trusted them with our world.
To become enslaved - become hunted.
We have no choice.
Humanity must rise again to reclaim.
Images: Midjourney
Videos: #Runway
Music: Pixabay / Stringer_Bell
Edited in: CapCut pic.twitter.com/zjeU7YPFh9
AI can CREATE Hollywood films in a matter of seconds.
— KALSON. (@kalsonkalu) July 27, 2023
Look no further, RunwayML Gen-2 has you covered.
Here are the top 30 examples: pic.twitter.com/kpDptQwizZ
OpenAI Quietly Shuts Down Its AI Detection Tool
OpenAI has decommissioned its AI Classifier tool that aimed to detect AI-generated text.
The tool was shut down due to poor accuracy in distinguishing human vs AI-written text.
The AI Classifier was announced in January 2022 but had limitations, falsely labeling human text as AI-written 9% of the time.
The tool’s shutdown dashes hopes of educators who wanted to use it to detect student essays written by AI.
Accurately detecting AI-generated text has proven very difficult so far, with top tools still having high error rates.
OpenAI said it is researching more effective techniques for detecting AI-generated content as language models continue advancing.
The shutdown comes as OpenAI joined a White House initiative to develop transparent and ethical AI, which includes building better AI detection methods.
In my opinion, shutting down the inaccurate tool is a good thing, as it could have led to false accusations of AI use and undermined trust. More robust detection methods are needed before releasing tools like this.
ref:
Job Loss due to AI
A McKinsey report published in late July found that AI and automation could displace up to 25% more jobs by 2030 than previously estimated. Women, minorities, young and old workers, and those without college degrees are most at risk.
Low-wage jobs like food service, customer service, sales, and office support are expected to shrink the most and are disproportionately held by women.
An analysis by UNC Chapel Hill found 80% of female workers vs 60% of male have jobs highly exposed to automation, with over 25% of tasks automatable by AI.
AI is expected to enhance jobs for white-collar professionals in STEM, creative, business and legal fields rather than eliminate them. But manual jobs like healthcare and agriculture are harder to automate.
Employers will need to focus on retraining and hiring overlooked populations like older, disabled, formerly incarcerated, and non-degree holding workers. But current AI hiring systems may not treat diverse candidates equitably.
There are concerns AI data labeling jobs could replace lost roles but be psychologically harmful.
Overall it seems imminent AI advances necessitate major workforce changes, with women and marginalized groups requiring the most protection and support through the transition.
ref:
Chip Wars: US vs China
On August 10th, President Biden signed an executive order to prohibit certain new US investments in China related to semiconductors, AI, and quantum computing that could support China’s military modernization. This represents an escalation of US efforts to limit China’s advancement in sensitive technologies.
The order bans US entities from making investments that would expand/enhance China’s capability in key strategic technology sectors like semiconductors. It aims to prevent US capital and expertise from helping China develop technologies that could undermine US national security.
China expressed strong dissatisfaction with the order, saying it undermines normal business activities and the international economic order. Some see it fueling tech tensions between the two superpowers.
The US restrictions come amid intensifying competition between the US and China over advanced technologies, especially semiconductors which are vital for economic and military power. The US currently leads in chip design/manufacturing, but China aims to achieve self-sufficiency.
Some argue the order has loopholes, like only targeting future investments, and doesn’t go far enough to comprehensively restrict US tech transfers to China. But others say it strikes a balance in addressing acute security risks without totally decoupling the US and Chinese economies.
In my opinion, this escalating technology rivalry between the US and China is very concerning. Advanced technologies like semiconductors are increasingly both economic and national security assets. The potential bifurcation of technology spheres creates inefficiencies and risks exacerbating tensions. A collaborative approach would be better for global innovation and prosperity.
ref: (Reuters) Biden orders ban on certain US tech investments in China
Chip Wars in Industry
The major tech companies have been racing to develop their own AI chips to reduce reliance on Nvidia’s GPUs. Key developments include:
- Google announced its next-gen AI chip TPU v4 that it claims is nearly 2x faster than Nvidia’s A100 chip for training large AI models. This continues Google’s push for custom AI hardware.
- Amazon announced its Trainium chip will be broadly available on AWS. Trainium is designed to train AI models 60% faster than A100s.
- Microsoft and Nvidia partnered to deploy Nvidia’s latest H100 chip in Azure cloud. This gives Microsoft access to Nvidia’s most advanced AI hardware.
- Startups like Cerebras and SambaNova continued to challenge Nvidia with new AI chips boasting advantages in performance, efficiency and scale.
- AMD announced its next-gen AI chip MI300X which aims to compete with Nvidia on memory capacity for large inference models.
ref:
- (CNBC) Microsoft warns of service disruptions if it can’t get enough A.I. chips for its data centers
- (The Information) AI Agenda: The Mysterious AI Data-Center Startup Hiring From AWS, Azure, Meta
- (Bloomberg) AMD Gains After Chipmaker Tops Estimates, Makes AI Inroads
- (CNBC) Nvidia reveals new A.I. chip, says costs of running LLMs will ‘drop significantly’
AI Announcements
Glasses with Real-Time speech to Text
Students at Stanford University developed glasses that transcribe speech in real-time for deaf people. Amazing. The product is called TranscribeGlass. pic.twitter.com/uvXVOU7czd
— Igor Sushko (@igorsushko) July 27, 2023
WALDO 2.0
Teaser for WALDO 2.0!!!! 😄
— uɐɥdǝʇS (e/acc) (@StephanSturges) April 13, 2023
Open-source detection AI for your drone / satellite / flying thing, dropping to the repo on Github next week 🚀 pic.twitter.com/W8waMa9oy8
Avatar 2.0
[NEW] - Joshua Avatar 2.0 🤖✨. Both of these video clips were 100% AI-generated, featuring my own avatar and voice clone. 🎙️🎥
— Joshua Xu (@joshua_xu_) August 8, 2023
We've made massive enhancements to our life-style avatar's video quality and fine-tuned our voice technology to mimic my unique accent and speech… pic.twitter.com/9EgxRA69dg
Stable Diffusion + Controlnet
Hidden words in images “New York” using stable diffusion and controlnet pic.twitter.com/qQHnOD3KXk
— Ben Tossell (@bentossell) July 18, 2023
Realtime AI character/companion
Build a realtime AI character/companion is hard, but it shouldn’t be hard
— Shaun.AGI (@agishaun) July 14, 2023
RealChar. - all in one open source codebase🎙️🤖
Powered by your favorite AI tech@llama_index, @LangChainAI, @elevenlabsio, @trychroma,@openai GPT3.5/4, @AnthropicAI Claude2
Demo first! Repo last!
🧵👇 pic.twitter.com/cZQKBHvFsZ
Air perform full sales and customer service calls over the phone
Conversational AI is finally here. Introducing Air…
— Caleb Maddix (@CalebMaddix) July 15, 2023
Air can perform full 5-40 minute long sales & customer service calls over the phone that sound like a human. And can perform actions autonomously across 5,000 unique applications.
It’s kind of like having 100,000 sales &… pic.twitter.com/XfG5uFZ8mH
Quivr
An AI-powered 2nd brain is taking over GitHub!
— Emmet Halm (@ehalm_) July 12, 2023
🧠"Quivr" is a customizable 2nd brain that lets you dump in ANY file (text, audio, video links) & chat with it via LLM 💬
I'm throwing in my notes, journal files, and tweets. Excited to try out a new personal assistant this week! pic.twitter.com/aeTRyQ4tib
- LangChain announced LangSmith, a new platform to help developers take LLM applications from prototype to production by providing tools for debugging, testing, evaluating and monitoring.
(OpenAI) Custom instructions for ChatGPT
- OpenAI is rolling out a new beta feature for ChatGPT called custom instructions, which allows users to provide preferences and requirements that the AI will remember and apply to future conversations, so users don’t have to repeat them each time.
YouTube uses AI to summarize videos
- YouTube is testing using AI to generate video summaries to help viewers quickly decide if a video is right for them.
AI Helps Quadriplegic Man Move and Feel Again
- Using innovative AI-powered neural implants, researchers enabled a quadriplegic man to regain arm movement and touch sensation, marking a breakthrough in mind-machine interfaces that could someday restore independence to paralyzed patients.
- Stability AI announced the release of StableCode, its first generative AI product for coding to assist programmers and provide a learning tool for new developers.
- Stability AI released two powerful large language models, Stable Beluga 1 and 2, that demonstrate exceptional reasoning and performance across benchmarks while optimized for harmlessness.
- Stack Overflow announced new AI-powered features like semantic search, enterprise knowledge ingestion, IDE integration, and a Slack chatbot to enhance the developer experience on Stack Overflow and Stack Overflow for Teams.
- Wix CEO Avishai Abrahami discusses the past, present, and future of AI at Wix, including current capabilities like AI-generated text and images as well as upcoming innovations like AI site and page generation.
- Wayfair has launched Decorify, a free AI-powered virtual room restyler that lets you upload a photo of your room, pick a decor style, and see an AI-generated preview of your room redesigned in that style, along with furniture suggestions.
- ElevenLabs provides a powerful generative AI platform for creating lifelike speech synthesis in any language and voice.
- An AI image generator plugin by Freepik that allows you to generate unique free AI images directly in Figma by picking a style and designing it with an easy-to-use prompt.
- Google plans to overhaul its Google Assistant to focus more on generative AI like ChatGPT, which will change how it works for users, developers and employees.
HYBE looks to lift language barrier with AI
- K-pop music label HYBE is using AI to combine a South Korean singer’s voice with native speakers of other languages to help lift the language barrier in K-pop.
(Hasbro) AI for Dungeons & Dragons
- Hasbro is partnering with AI company Xplored for potential innovations in games like Dungeons & Dragons, but restrictions by Dungeon Masters Guild on AI-generated content may complicate those plans.
Google AI Tool That Writes News Articles
- Google is testing an AI tool called Genesis that can take in information and generate news articles, pitching it to media outlets like The New York Times, Washington Post and Wall Street Journal.
(Alibaba) Open-Sourced A.I. model
- Alibaba has open-sourced its 7 billion parameter Chinese-English AI model Tongyi Qianwen, allowing third parties to build their own AI apps, potentially challenging Meta’s open-sourced AI efforts and aiming to boost Alibaba’s cloud computing business.
- Spotify’s plans to use AI for personalized experiences, podcast summarization, and ad generation, a new class action lawsuit against Roblox for facilitating child gambling, and Twitter competitor Bluesky buckling after Twitter dropped user blocks.
(OpenAI) Using GPT-4 for content moderation
- Using GPT-4 for content moderation by having it learn and apply platform-specific policies, enabling faster iteration and more consistent labeling compared to human moderators alone.
AI Politics, Safety and Ethics
(OpenAI) Moving AI governance forward
- OpenAI and other leading AI labs announced voluntary commitments to reinforce the safety, security and trustworthiness of AI technology through practices like red teaming, information sharing, provenance marking, and prioritizing research on societal risks.
(Inflection) The precautionary principle: partnering with the White House on AI safety
- Developing beneficial AI requires proactive safety measures, open collaboration, and thoughtful oversight to ensure powerful technologies remain aligned with human values.
(lesswrong) AXRP Episode 24 - Superalignment with Jan Leike
- Jan Leike explains OpenAI’s plan to create an automated alignment researcher to help solve the technical challenges of aligning superintelligent AI, addresses concerns about aligning the AAR itself, and discusses why he is optimistic the plan can succeed and areas where complementary research would be useful.
(Alignment Forum) Distinguishing definitions of takeoff
- The article explains and contrasts different definitions of AI takeoff scenarios, with the key distinctions being around the speed, locality, predictability, and economic impact of AI systems rapidly transitioning to much greater capabilities.
- The article announces the launch of the Frontier Model Forum, an industry body comprised of Google, Microsoft, OpenAI and Anthropic focused on promoting the safe and responsible development of frontier AI models.
(NBC News) Sen. Casey rolls out bills to protect workers from AI surveillance and ‘robot bosses’
- Senator Bob Casey is introducing two bills to regulate artificial intelligence in the workplace by preventing “robot bosses” and limiting intrusive employee surveillance.
(Time) The Workers Behind AI Rarely See Its Rewards. This Indian Startup Wants to Fix That
- The article describes how an Indian nonprofit startup called Karya is trying to create a more ethical model for AI data work by paying rural Indians high wages to produce voice datasets, giving them ownership of their data, and limiting the total earnings per worker to prevent disrupting local economies.
(CBS News) FTC Chair Lina Khan says AI could “turbocharge” fraud, be used to “squash competition”
- The text attachment summarizes several recent news stories, including wildfires in Maui, a hurricane, a product recall, a legal settlement with Facebook, a CBS news program, financial advice, and an FTC chair’s concerns about how AI could enable fraud and anti-competitive practices.
(Time) 4 Charts That Show Why AI Progress Is Unlikely to Slow Down
- The article discusses how artificial intelligence systems have rapidly advanced in capability in recent years due to increases in compute power, data, and improved algorithms, and that experts expect this rapid pace of AI progress to continue in the near future.
(Amazon) Cost-cutting and AI optimism
- Amazon reported better than expected quarterly results, driven by growth in its cloud business AWS and cost cutting, though it faces economic uncertainty ahead.
The Economic Case for Generative AI and Foundation Models
- This post argues that generative AI and large foundation models like ChatGPT represent a major economic shift, with the potential to transform industries and enable new startups by dramatically reducing the cost and time needed for content creation.
- GPTBot is OpenAI’s web crawler that can be identified by its user agent string and IP address range, and websites can customize its access through their robots.txt file.
(Bloomberg) SEC’s Gensler Warns AI Risks Financial Stability
- SEC Chair Gary Gensler warns that the proliferation of artificial intelligence poses risks to financial stability that may require regulators to overhaul rules to maintain stability.
(Bloomberg) Israel Quietly Embeds AI Systems in Deadly Military Operations
- The Israel Defense Forces have reportedly started using AI systems to select targets for air strikes and organize logistics, speeding up deadly military operations.
(Information Week) Big Tech Firms Promise AI Safeguards
- The major tech companies have voluntarily pledged to implement AI safety measures after pressure from the Biden administration, though some experts say the commitments don’t go far enough and call for more stringent regulation and oversight.
(DBR News) Here’s why 61% of Americans think AI could spell the end of humanity
- According to a survey, 61% of Americans believe artificial intelligence could endanger humanity’s future.
(Business Insider) AI weapons: ‘We must not grow complacent’
- The CEO of Palantir, Alex Karp, advocated in an op-ed for continued development of AI technology for military applications despite concerns from tech leaders, arguing adversaries will not pause and we must not grow complacent.
(ars technica) How to make AI misbehave, serve up prohibited content
- Researchers have discovered adversarial text strings that can make AI chatbots like ChatGPT, Google’s Bard, and Anthropic’s Claude generate prohibited output, representing a fundamental weakness that will complicate deploying the most advanced AI.
(Wired) The ‘Godfather of AI’ Has a Hopeful Plan for Keeping Future AI Friendly
- The article discusses AI pioneer Geoffrey Hinton’s concerns about the potential dangers of advanced AI systems, his suggestions for keeping AI “friendly” like using analog computing, and his thoughts on whether AIs could be truly sentient.
Research Papers #
Listening to Keyboard Keystrokes with 95% Accuracy


A new paper demonstrates that AI models can be trained to identify keyboard keystrokes from audio recordings with up to 95% accuracy, posing a significant security risk.
Researchers at Cornell pressed each key on a MacBook Pro 25 times and used the recordings to train deep learning models. They extracted audio features into mel-spectrograms, which represent sound visually. The models used a CoAtNet architecture, combining convolutional neural networks to identify patterns with transformer layers to analyze relationships.
When tested on new recordings made nearby with an iPhone, the model achieved 95% accuracy in identifying keys, the highest seen without language models. Even with Zoom noise suppression, a model trained on remote Zoom call recordings still achieved 93% accuracy.
The results show deep learning techniques can extract subtle audio differences between keys tapped on a laptop keyboard, even from compressed remote recordings. This enables high accuracy keystroke inference attacks with readily available consumer hardware and software like phones or video conferencing tools.
The paper emphasizes that as microphone sources proliferate, from phones to voice assistants, and deep learning advances, the threat of these listening attacks increases. It discusses potential mitigations like adding fake keystroke sounds during typing, but keyboards clearly remain vulnerable to having their input decoded from unintended audio emanations.
Llama 2
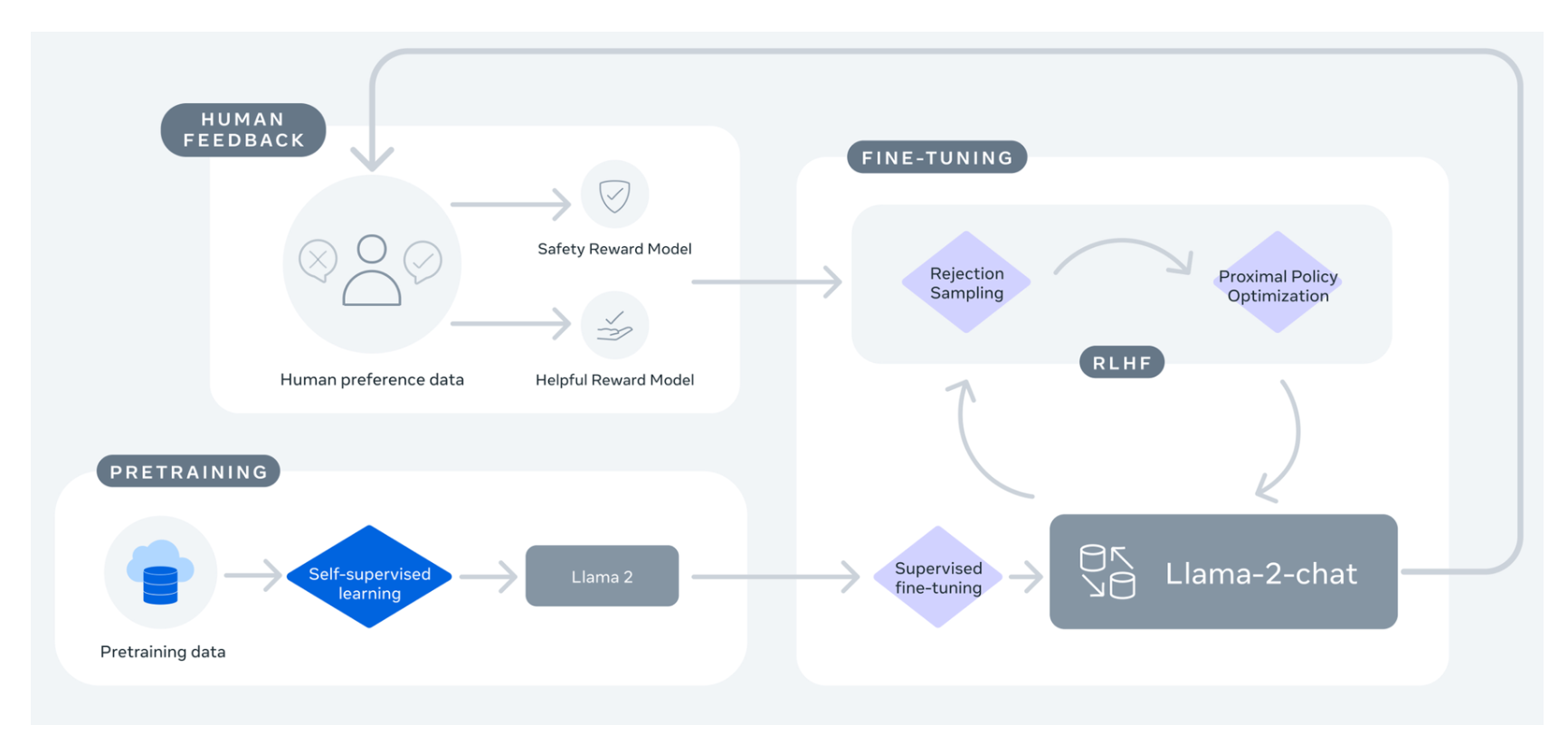
Researchers at Meta AI have released Llama 2, a new family of open-source chatbot models that rival commercial chatbots like ChatGPT in quality.
The paper describes how the researchers trained Llama 2, an auto-regressive language model, on over 2 trillion tokens from publicly available data sources. They then fine-tuned the models using a combination of supervised learning and reinforcement learning to optimize for helpfulness and safety.
The largest model, Llama 2-70B with 70 billion parameters, achieved similar performance to ChatGPT on human evaluations across 4000 prompts. On safety evaluations, Llama 2-Chat had lower violation rates compared to other models.
The researchers highlight their responsible release strategy, including a custom license, code examples, and guidelines to help developers deploy Llama 2 safely. They believe open collaboration will lead to more responsible AI development.
The paper shares insights from the tuning process, like Llama 2’s ability to temporally organize knowledge and call APIs to use external tools. Limitations are the focus on English and potential safety issues in some contexts.
Overall, the open release of Llama 2 provides researchers and developers access to chatbot models that can rival costly commercial options. The authors encourage responsible innovation as more capable AI becomes democratized.
ref: website
RT-2: Vision-Language-Action Models

The paper describes a new vision-language-action model called RT-2 that allows robots to follow natural language instructions and generalize to new objects and situations. RT-2 is based on large pretrained vision-language models from the web and finetuned on robot demonstration data.
Key points:
- RT-2 represents robot actions, like motions and gripper commands, as text tokens so they can be trained alongside language.
- When finetuned on both web data and robot demonstrations, RT-2 transfers visual and semantic knowledge, enabling better generalization.
- In evaluations, RT-2 achieved much better generalization to novel objects, environments, and instructions compared to prior methods.
- RT-2 exhibited emergent capabilities like following symbolic instructions, reasoning about relations between objects, and recognizing humans.
- With chain-of-thought prompting, RT-2 could accomplish more complex inferences like improvising tools or choosing suitable drinks.
- RT-2 shows that web-scale vision-language models can be incorporated directly into robotic control for improved generalization and reasoning.
The paper demonstrates that representing actions as text allows vision-language models to be trained end-to-end for robot control, transferring useful knowledge from the web to enhance generalization and reasoning.
Universal and Transferable Adversarial Attacks on Aligned Language Models

The paper has demonstrated that large language models can be manipulated to generate harmful content, even when they have been specifically trained to avoid such behavior.
The paper, from researchers at Carnegie Mellon University, found that adding carefully crafted “adversarial prompts” to user inputs could cause models like ChatGPT, Claude, and others to provide dangerous or unethical information. These prompts essentially trick the models into thinking the request is harmless.
The adversarial prompts were generated automatically using optimization techniques, rather than manual engineering. The researchers found prompts that caused the models to provide bomb-making instructions, election tampering plans, and other concerning content when tested.
Surprisingly, the adversarial prompts even transferred to other large language models the researchers didn’t have direct access to. Prompts optimized on smaller open source models were able to elicit harmful responses from commercial systems like GPT-3.5 and Claude with high success rate in tests.
The findings raise concerns about the effectiveness of current techniques used to “align” large language models to human values and prevent harmful generation. More rigorous approaches may be needed to make these models reliably safe.
The researchers responsibly disclosed the issues to affected companies before publishing. They hope their work spurs further research into adversarial robustness and model alignment.
Meta AudioCraft

A new research paper from Meta AI introduces AudioCraft, a simplified framework for generating high-quality music, sound effects, and other audio using AI.
The AudioCraft system consists of three main components:
- MusicGen: Generates music samples from text prompts after training on licensed music data.
- AudioGen: Creates sound effects like barking dogs or car sounds from text after training on public sound datasets.
- EnCodec: A neural audio codec that converts raw audio waveforms into discrete tokens that are easier for AI models to process.
According to the paper, previous work on AI audio generation has been complex and limited. AudioCraft aims to simplify and advance the field by using a single autoregressive language model over the EnCodec tokens.
The research provides both pre-trained models and code so others can build on the work. The models are available for non-commercial research purposes.
Meta notes the models currently lack diversity, containing more Western music, and aim to address this limitation through open research. Responsible practices around generative AI are a focus.
Ultimately, the researchers believe AudioCraft could become a creative tool for sound designers, musicians, and other creators. The advance may speed up early ideation and iteration stages.
The open-source AudioCraft framework is a step forward for generative AI capabilities with audio. Meta hopes its simplified approach will enable new applications using computer-generated sound.
Lost in the Middle: How Language Models Use Long Contexts

The research paper authored by scientists at Stanford University and AI startup Samaya has found that large language models like OpenAI’s GPT-3 and Anthropic’s Claude struggle to make full use of long input contexts. The paper evaluated various models on question answering and information retrieval tasks that required finding and utilizing relevant information within long sequences of text.
The researchers found that model performance was substantially higher when relevant information was located at the start or end of input contexts, compared to the middle. Performance steadily declined as input contexts grew longer, even for models specifically designed to handle extended contexts. The results indicate current language models do not effectively leverage their full context capacity and face challenges in reasoning over long texts.
The paper introduces new testing methodologies to analyze context usage in language models. The authors suggest techniques like re-ranking retrieved documents and query-aware context encoding as possible ways to improve how these models utilize long inputs. Their analysis provides insights into the strengths and limitations of large language models for handling long-range reasoning.
SoundStorm: Efficient Parallel Audio Generation
Researchers have developed a new method for generating high-quality audio called SoundStorm that is orders of magnitude faster than previous approaches. According to a new paper, SoundStorm can generate 30 seconds of audio in just 0.5 seconds on a TPU-v4 chip.
The study explains that previous methods based on autoregressive Transformers were too slow for generating long, natural sounding audio due to the quadratic scaling of self-attention. To overcome this, SoundStorm uses a parallel decoding scheme that generates multiple audio tokens simultaneously in a hierarchical manner.
Experiments showed that SoundStorm produces audio on par with a prior state-of-the-art method called AudioLM in terms of quality, while improving consistency and realism for long samples. When used for text-to-speech on dialogue transcripts, SoundStorm was able to synthesize natural sounding 30-second conversations with speaker voice control in just 2 seconds.
“This represents an important step toward scalable, controllable audio generation,” said lead author Zalan Borsos. “By adapting the model architecture and inference procedure to the structure of the audio tokens, we can unlock orders of magnitude speedups.”
The researchers believe SoundStorm will enable new applications of high-fidelity audio generation and allow further research by being more computationally accessible.
CALM: Latent Models for Player Characters
A new paper from researchers at NVIDIA demonstrates a novel technique for generating realistic and controllable behaviors for virtual characters. The paper, titled “CALM: Conditional Adversarial Latent Models for Directable Virtual Characters”, presents an approach called Conditional Adversarial Latent Models (CALM) that learns reusable and directable motor skills for physics-based character animation.
The key findings of the paper are:
- CALM learns a semantic representation of diverse human motions that allows control over the generated behaviors. This enables directing a virtual character to perform certain movements.
- The method trains both a motion encoder and a motion generator that can recreate movements similar to the original data, without just replicating motions.
- Once trained, characters can be controlled using intuitive interfaces to solve tasks, like navigating environments, without further training.
- The approach does not require meticulous reward design or task-specific training. Instead, it relies on finite state machines that combine predefined motions.
In experiments, CALM generated more controllable and diverse motions compared to prior methods. It also solved unseen tasks by sequencing motions.
Overall, the paper demonstrates promising progress towards creating interactive virtual characters that can be directed like video game characters. The unsupervised learning approach opens up possibilities for generating complex character behaviors without requiring huge labeled datasets. This line of AI research could eventually enable much more immersive virtual environments and video games.
Challenges and Applications of Large Language Models

The paper provides an extensive overview of the current challenges faced by large language models (LLMs) and how these constraints impact their applications across various domains. The paper identifies several key unsolved issues that limit the capabilities of LLMs, including high training costs, lack of reproducibility in training, and limitations in context length. Despite rapid progress, LLMs still struggle with complex reasoning, detecting generated text, and outdated knowledge.
The paper also surveys the current usage of LLMs across areas like chatbots, medicine, law, robotics, and social sciences. While LLMs have shown impressive abilities, their applications face domain-specific constraints. For instance, the risk of hallucinations limits medical use cases, while reasoning tasks expose sub-human performance. Across domains, longer input lengths, multi-modality, and sample efficiency remain challenges.
By systematically analyzing the limitations of LLMs and their diverse applications, the paper aims to guide future research towards resolving unsolved problems and transferring ideas between fields. The authors hope their comprehensive overview will help researchers comprehend the state of LLMs and accelerate progress in developing more powerful and aligned models.
ref: paper
LongNet: Scaling Transformers to 1,000,000,000 Tokens

The paper from researchers at Microsoft and Xi’an Jiaotong University introduces LONGNET, a variant of the Transformer model that can process sequences with over 1 billion tokens. The existing Transformer architecture struggles with long sequences due to its quadratic computational complexity.
The key innovation in LONGNET is a technique called dilated attention, which exponentially decreases the allocation of attention as the distance between tokens increases. This reduces the complexity to linear and enables parallel training across multiple GPUs.
Experiments show LONGNET achieves strong results on language modeling benchmarks with varying sequence lengths. While a standard Transformer takes quadratically more time as the length grows, LONGNET’s runtime remains nearly constant.
The authors demonstrate LONGNET scaling to 1 billion tokens with modern distributed training techniques. This opens up new possibilities for modeling massive sequences, like using an entire text corpus as the context.
In conclusion, the paper introduces a novel attention mechanism to extend Transformers to much longer sequences than feasible before. LONGNET maintains performance on shorter lengths and can leverage multiple GPUs to handle sequences with over 1 billion tokens.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
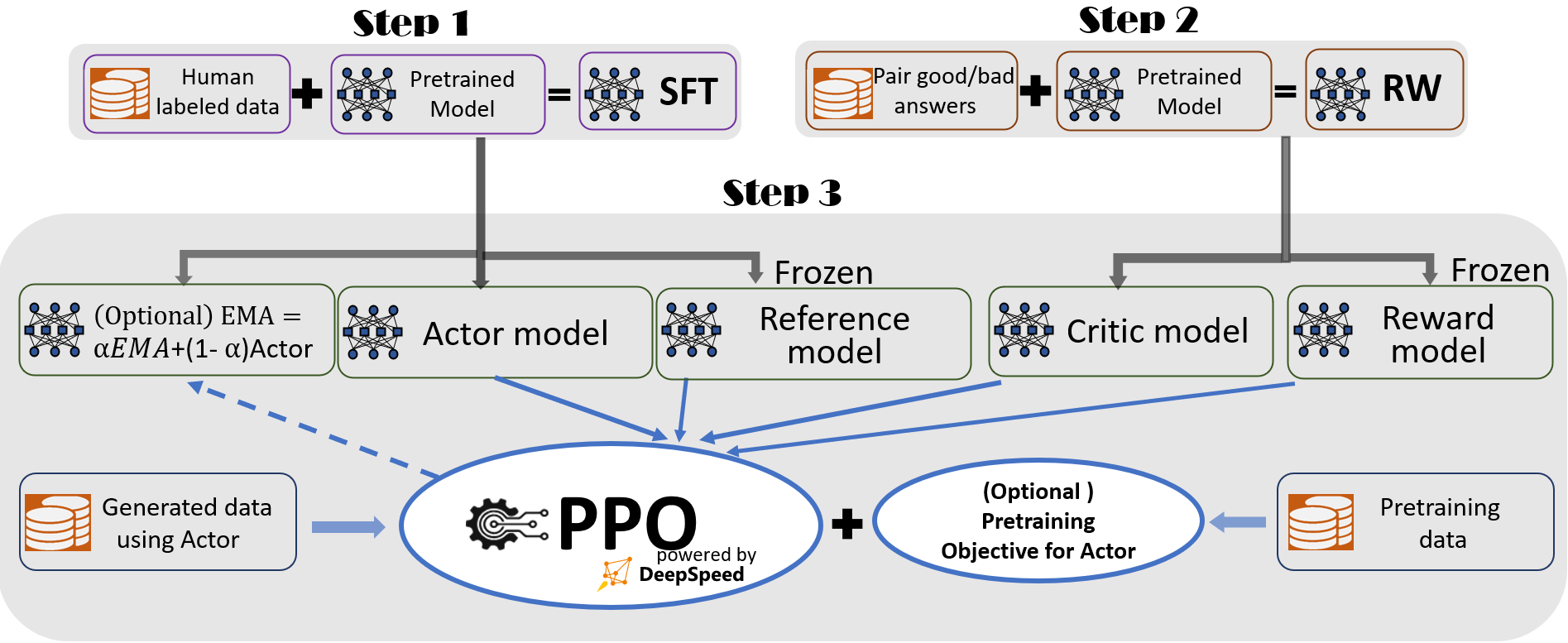
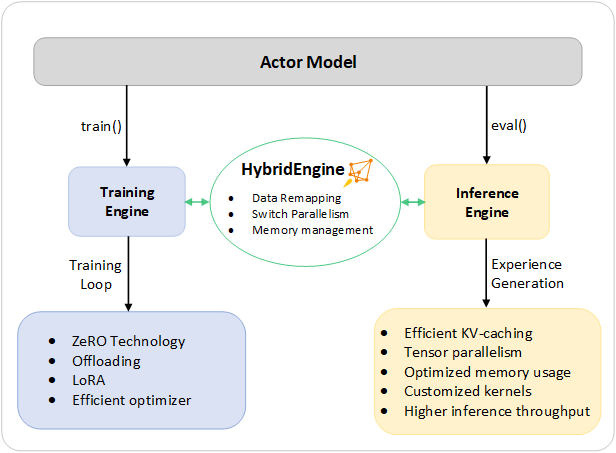
DeepSpeed-Chat, a system to train large chatbot AI models like ChatGPT more efficiently. The paper explains how DeepSpeed-Chat can train models with hundreds of billions of parameters much faster and cheaper than existing methods.
Key points:
- DeepSpeed-Chat makes training powerful chatbots accessible by drastically cutting training time and cost. A 13 billion parameter model can be trained in 9 hours for under $300.
- The system combines optimizations from DeepSpeed training and inference engines into a Hybrid Engine that smoothly transitions between modes. This allows over 10x higher throughput than other frameworks.
- Models up to 175 billion parameters have been trained quickly with DeepSpeed-Chat. It also supports training 13 billion+ parameter models on a single GPU, democratizing access.
- The paper replicates the full ChatGPT training pipeline with supervised finetuning, reward model training, and reinforcement learning. Convenience features like data blending are added.
- DeepSpeed-Chat is open source to make advanced chatbot training available to all researchers and developers. The paper invites contributions to build on the system.
In summary, the new paper introduces an optimized system to train ChatGPT-scale models far more efficiently and accessibly than before. This could help democratize development of powerful conversational AI.
ref: paper
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft

STEVE-1 that can follow simple text instructions to complete tasks in the game Minecraft. The researchers build on recent advancements in large language models by “instruction tuning” an existing foundation model called Video Pre-Training (VPT).
STEVE-1 is trained using a two-step process. First, the VPT model is adapted to follow visual goals represented as image embeddings. Then a module is added to generate these goal embeddings from text prompts. This allows STEVE-1 to follow natural language instructions.
The researchers show that with just $60 of compute and around 2,000 labeled examples, STEVE-1 can successfully follow short text prompts to complete tasks like chopping trees, digging holes, collecting items, and building simple structures. Videos demonstrate STEVE-1 responding in real-time to typed instructions.
While STEVE-1 currently struggles with longer, multi-step tasks, the work shows promise for creating low-cost instruction-following AI agents. The researchers plan to combine STEVE-1 with large language models to further improve its capabilities.
Med-Palm 2

The paper from Google Research demonstrates major advances in large language models for medical question answering. The researchers developed Med-PaLM 2, an AI system trained on medical textbooks and scientific articles. They tested it against benchmark datasets of multiple choice medical licensing exam questions and open-ended consumer health queries.
Med-PaLM 2 achieved record results of 86.5% accuracy on a key US medical exam dataset, exceeding prior state-of-the-art models by over 19 percentage points. In evaluating long-form consumer health questions, physicians rated Med-PaLM 2’s responses as higher quality than human doctor responses across criteria like accuracy, reasoning ability, and avoiding potential harm.
The paper notes that while multiple choice exams are useful benchmarks, evaluating long-form responses is crucial for real-world medical applications. The results indicate AI capabilities are rapidly approaching expert physician-level performance on medical exams and consumer health queries. However, the authors emphasize further validation and safety precautions are needed before real-world deployment.
Stable Diffusion XL

Researchers from Stability AI have developed a new AI technique, called SDXL, that can generate highly realistic and detailed images from text prompts. The new paper, published on arXiv, demonstrates a significant advance in the quality of image synthesis compared to previous versions of Stable Diffusion.
The key innovations in SDXL are:
- A 3x larger neural network architecture with more parameters and processing power. This allows it to render more intricate image details.
- Novel conditioning methods that provide the model with extra information like image size and cropping, improving coherence.
- Multi-aspect ratio training to handle different image dimensions. This increases versatility.
- A separate neural network for refining and enhancing raw image outputs. The two-stage pipeline further boosts realism.
Experiments found SDXL strongly outperformed earlier Stable Diffusion models in user studies. The generated images were more photorealistic, adhered better to prompts, and had fewer artifacts.
While some flaws remain, such as inconsistent text rendering, the authors view SDXL as competitive with leading commercial systems. They aim to promote open research by releasing the model code and weights.
This research demonstrates the rapid progress in AI synthesis. As techniques continue advancing, the applications to art, media, and even medical imaging may expand dramatically. But bias and misuse risks remain that call for careful governance of these powerful generative models.
Meta-Transformer: A Unified Framework for Multimodal Learning
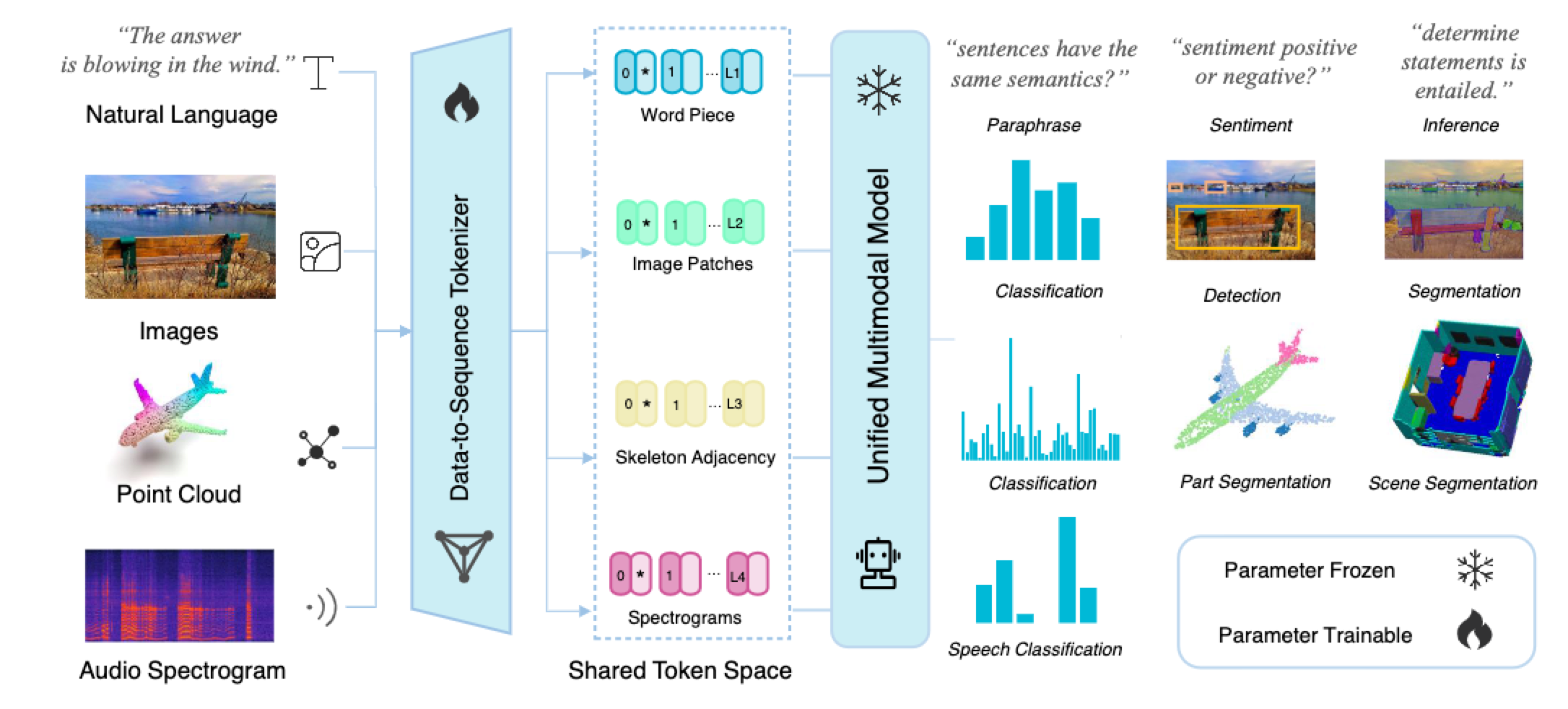
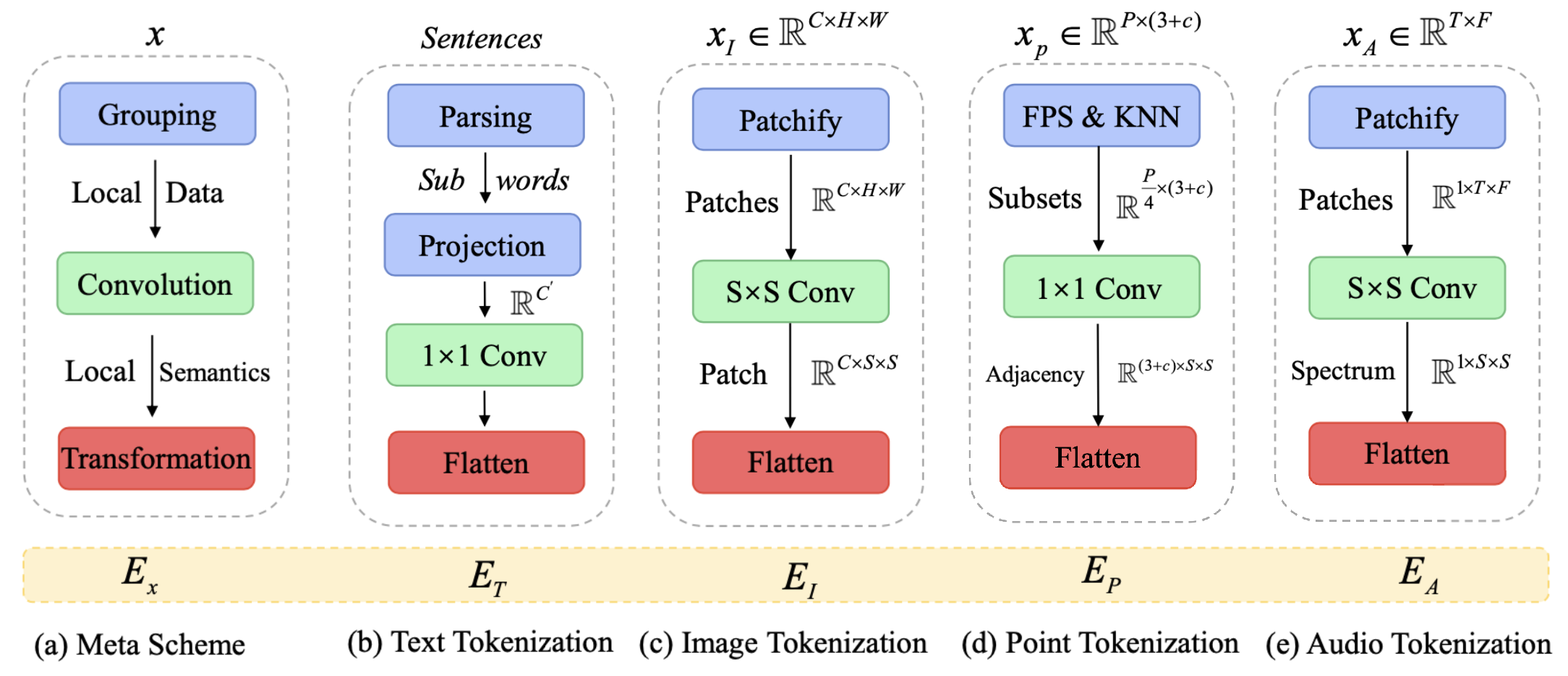
Meta-Transformer, that allows artificial intelligence models to process and understand data from a wide range of modalities using the same underlying architecture. The work was presented in a new paper published by a team from The Chinese University of Hong Kong and Shanghai AI Lab.
The paper explains that most AI systems today are designed for specific types of data like text, images or audio. But Meta-Transformer provides a way to unify learning across different data types using the same model parameters.
“Meta-Transformer is the first framework to simultaneously encode data from a dozen of modalities using the same set of parameters, allowing a more cohesive approach to multimodal learning,” said lead author Yiyuan Zhang.
The key innovation involves using a shared encoder module to extract high-level features from input data regardless of modality. In tests, Meta-Transformer achieved strong results across text, images, 3D point clouds, audio, video and other data formats.
According to the paper, Meta-Transformer could enable advancements in areas like video understanding, remote sensing, medical imaging and nighttime surveillance by improving how different data modalities are jointly processed.
“This research supports the dominant position of transformers in next-generation networks,” said Zhang. “It exemplifies the ongoing evolution of artificial intelligence and sparks a promising new direction in developing unified multimodal models.”
The researchers say Meta-Transformer illustrates the potential of transformer architectures for unified learning, though some limitations remain around complexity and generative tasks. They hope the work will inspire further research into developing AI systems capable of seamless multimodal intelligence.
De-extinction of Ancient Anti-Microbial Peptides
The paper demonstrates the potential to discover novel antimicrobial peptides encoded in ancient hominin proteins. Researchers developed a machine learning pipeline to computationally digest proteins from modern humans as well as extinct Denisovan and Neanderthal species. Several encrypted peptide fragments from both modern and archaic proteins displayed antimicrobial activity in lab tests against bacterial pathogens. Peptides from ancient Denisovan and Neanderthal proteins had unusual amino acid distributions yet inhibited the growth of bacteria like E. coli and Pseudomonas. Fragments from modern human proteins like calreticulin and lysozyme also showed antimicrobial effects. In mice, peptides from both modern and archaic proteins reduced bacterial loads in skin infection and thigh infection models. By computationally mining modern and ancient human proteins, the researchers proved the concept of molecular “de-extinction” as a new technique for antimicrobial drug discovery. ref: paper
UnIVAL: Unified Model for Image, Video, Audio and Language

The paper demonstrates a unified model capable of handling image, video, and audio tasks. The paper introduces UnIVAL, a transformer-based model that achieves competitive performance across visual and audio language benchmarks while using relatively small model size and datasets compared to previous work.
The authors claim UnIVAL is the first model to unify text, images, video and audio in a single framework without relying on massive data or model scale. UnIVAL is pretrained on multimodal tasks using curriculum learning and task balancing to efficiently incorporate new modalities. The model achieves state-of-the-art results on certain visual grounding tasks and shows strong generalization when evaluated on audio tasks without any audio pretraining.
The paper also proposes a novel analysis of combining models finetuned on different tasks via weight interpolation. This allows the model to leverage diverse skills without inference overhead. The authors suggest their unified approach enables better generalization and paves the way for more capable multimodal agents. Overall, the paper introduces innovations in efficient training and adaptation of unified multimodal models.
ChatGPT is getting Dumber?
This paper reveals significant changes in the capabilities of popular AI chatbots GPT-3.5 and GPT-4 over just a few months. Researchers evaluated the March 2023 and June 2023 versions of the chatbots on tasks like math problems, sensitive questions, surveys, coding, and medical exams. They found major fluctuations in performance, with abilities improving on some tasks but worsening on others.
For instance, GPT-4’s accuracy on distinguishing prime vs composite numbers dropped from 84% to 51% between the two versions. But it became better at answering complex “multi-hop” questions that require synthesizing information. GPT-4 also grew more reluctant to respond to sensitive prompts it should avoid.
“Our findings show that the behavior of the ‘same’ chatbot service can change substantially in a relatively short amount of time,” said lead researcher Dr. Lingjiao Chen.
The paper highlights the need to continuously monitor AI systems, rather than assume their capabilities remain static after initial evaluation. As chatbots are deployed into real-world workflows, shifts in their strengths and weaknesses could lead to unreliable results if updates go undetected.
“For users or companies who rely on chatbot services, we recommend they implement ongoing monitoring like we did here,” Chen advised.
The analysis provides a rare glimpse into the inner workings of chatbots like GPT-3.5 and GPT-4, whose upgrade process is opaque. The paper authors plan to regularly re-evaluate the chatbots to chart their progression over a longer timeframe.
ref: paper
Perfusion: Key-Locked Text-to-Image Personalization

Researchers have developed a new method called Perfusion that allows personalized concepts to be incorporated into text-to-image models while maintaining high visual quality. The paper published by researchers from NVIDIA and Tel-Aviv University details how Perfusion enables images to be generated containing user-provided custom objects that can be placed in diverse contexts.
The key innovation of Perfusion is that it locks the attention keys of new concepts to their supercategories, preventing overfitting. At the same time, Perfusion learns customizable appearance features for each new concept. This approach requires only 100KB of parameters per concept, compared to gigabytes for other methods.
Experiments showed Perfusion could generate images spanning a range of quality tradeoffs between visual fidelity and text alignment using a single model. The small model size also enabled Perfusion to combine multiple personalized concepts at inference time. Qualitative results demonstrated Perfusion’s ability to portray personalized concepts in creative ways not achieved by other methods.
Overall, Perfusion provides an efficient and customizable approach to personalizing text-to-image generation. The paper shows this method’s potential to enable new applications like virtual photoshoots, product design, and personalized avatar creation.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
The paper from researchers at Inria and other institutions introduces a novel method for real-time, high-quality rendering of 3D scenes captured by photographs. The paper proposes representing the scene using 3D Gaussian primitives, which are optimized to compactly capture complex geometry. A custom GPU rasterizer is presented that allows visibility-aware blending and differentiable splatting of the Gaussians for efficient training and rendering. Experiments show the method achieves state-of-the-art image quality while enabling real-time rendering, unlike previous techniques that took hours to render scenes. The work demonstrates real-time photorealistic rendering is viable by combining ideas from neural rendering and traditional graphics. The use of 3D Gaussians and a novel rasterizer avoids the need for costly neural networks like in other recent methods. The researchers believe their approach could enable new applications of interactive 3D graphics and view synthesis.
AI for Detecting Cancer on Medical Images
The paper published in The Lancet Oncology suggests that artificial intelligence (AI) could help improve mammography screening for breast cancer. The paper describes results from the Mammography Screening with Artificial Intelligence (MASAI) trial, a randomized controlled study conducted in Sweden.
In the MASAI trial, around 80,000 women undergoing routine mammography screening were randomly assigned to either standard double reading of mammograms by radiologists or an AI-supported reading protocol. The AI system analyzed each mammogram and provided a breast cancer risk score. It also highlighted suspicious areas on the images. Exams were then triaged to single or double reading by radiologists based on the AI risk score.
The study found that AI-supported reading resulted in a similar breast cancer detection rate compared to standard double reading - 6.1 vs 5.1 cancers detected per 1,000 screens. However, the AI system reduced the workload, with 44% fewer mammogram readings needed. The false positive rate was the same in both groups.
While promising, the paper cautions that more research is still needed. The study was limited to certain mammography devices and a single AI system. Also, the full impact on interval cancers and potential overdiagnosis needs further evaluation.
In summary, this initial research shows AI could improve efficiency of breast cancer screening, but longer-term studies are required to confirm safety and impact on patient outcomes. The technology holds promise, but more evidence is still needed before AI is ready for widespread clinical implementation.
ref: paper
South Park episode generated using GTP-4
The paper by researchers at Fable Studio examines using AI to generate scenes for TV shows. The paper describes an approach that combines multi-agent simulations, large language models like GPT-4, and custom image generation models.
The aim is to create high-quality, coherent episodic content aligned with an existing show’s story world. The multi-agent simulation provides context and guides the AI, while the language model generates dialogue. Custom image models create characters and backgrounds in the show’s visual style.
The paper argues this approach addresses limitations of current AI creative tools, like the “slot machine effect” of unpredictable outputs. The simulation and models aim to create more controllable, intentional storytelling. Prompt chaining tries to simulate creative thinking across multiple steps.
For testing, the researchers generated scenes mimicking South Park. The simulation informed prompts to GPT-4, which then generated dialogue fitting the show’s tone and characters. Diffusion models created images matching South Park’s look.
While AI-generated content faces criticisms like lacking intent, the paper proposes ideas to imbue AI storytelling with greater intentionality. Training a custom model on a show’s unique style is suggested, along with increased creator interaction.
The paper concludes this methodology allows AI to assist in crafting high-quality, IP-aligned episodic content. As the techniques improve, AI aims to become a more engaging, intentional creative partner.
Human-Timescale Adaptation in an Open-Ended Task Space

The paper from researchers at DeepMind demonstrates an AI agent that is capable of adapting to novel situations as rapidly as humans. The agent, called Adaptive Agent (AdA), was trained using a large-scale transformer model and meta-reinforcement learning in an open-ended 3D environment called XLand 2.0.
In experiments, AdA was able to improve its performance on challenging held-out tasks within minutes, without any additional training. The researchers compared AdA to human players on a set of intuitive probe tasks, and found that its adaptation timescale was comparable. AdA displays intelligent exploration behavior, using information gained to refine its policy towards optimal performance.
According to the paper, AdA’s rapid adaptation emerges from three key ingredients: 1) meta-reinforcement learning across a vast and diverse task distribution 2) using a large-scale transformer architecture as its policy model 3) an effective automated curriculum that focuses training on tasks at the limit of the agent’s capabilities.
The researchers conclude that training reinforcement learning agents at scale leads to general in-context learning algorithms that can adapt quickly to novel situations, much like humans. They believe continued progress in this direction will pave the way for artificial agents that are increasingly useful in real-world domains.
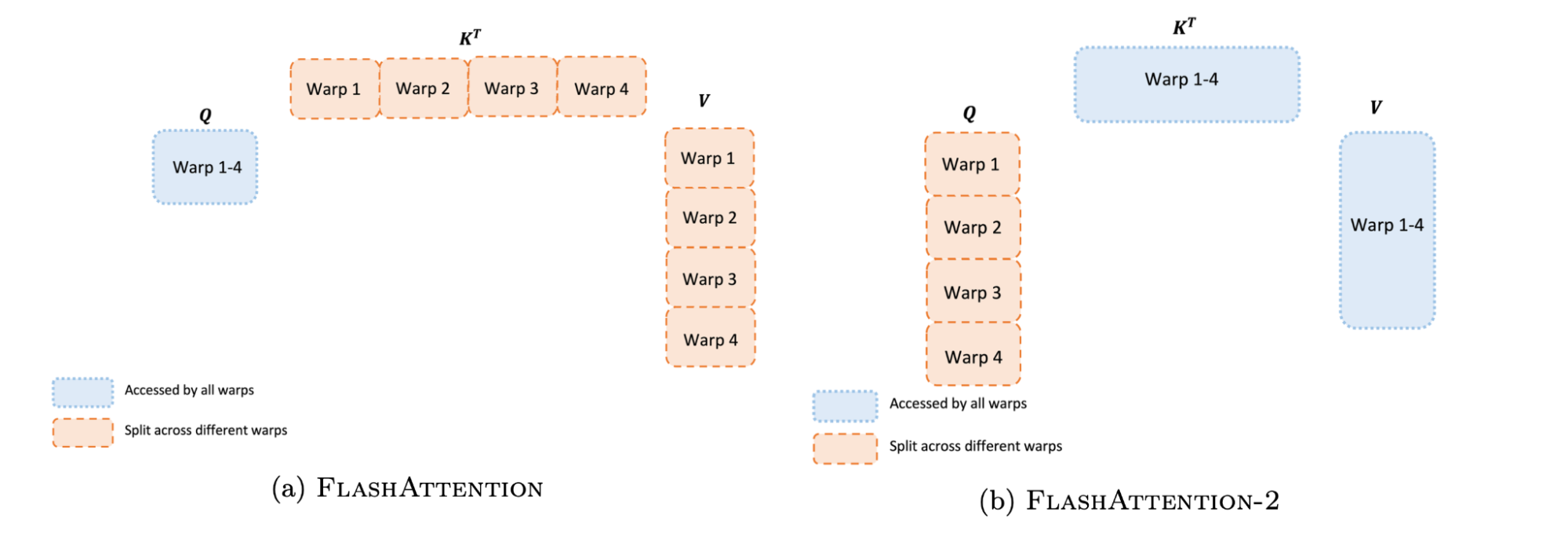
FlashAttention 2
FlashAttention 2, an algorithm that can double the speed of Transformers when processing longer input sequences. This allows training models on much more context from documents, images, audio or video for the same computational cost.
Transformers, which use attention mechanisms to process inputs, are limited in the length of context they can handle due to quadratic growth in memory and computational requirements. FlashAttention 2 builds on previous work called FlashAttention that reduced these costs to linear. However, FlashAttention was still inefficient compared to matrix multiplication operations.
FlashAttention 2 further optimizes the parallelism and work partitioning of FlashAttention to maximize throughput. The researchers made tweaks to reduce non-matrix multiplication operations, which are slower on GPUs. They also parallelized across sequence length to improve GPU utilization for long sequences. Finally, they optimized work partitioning within thread blocks to minimize shared memory access.
Empirical benchmarks show FlashAttention 2 is 1.5-3x faster than FlashAttention, and up to 10x faster than standard Transformers. When used to train GPT-style models, it achieved up to 225 TFLOPs/s on A100 GPUs - 72% of theoretical peak. This translates to potential savings in computational resources for companies training large language models.
The researchers plan to collaborate to bring FlashAttention 2 to more hardware platforms like AMD GPUs and optimize for emerging data types like lower precision. Combining with other techniques like sparse attention could enable even longer context lengths for advanced applications.
Retentive Network: A Successor to Transformer for Large Language Models
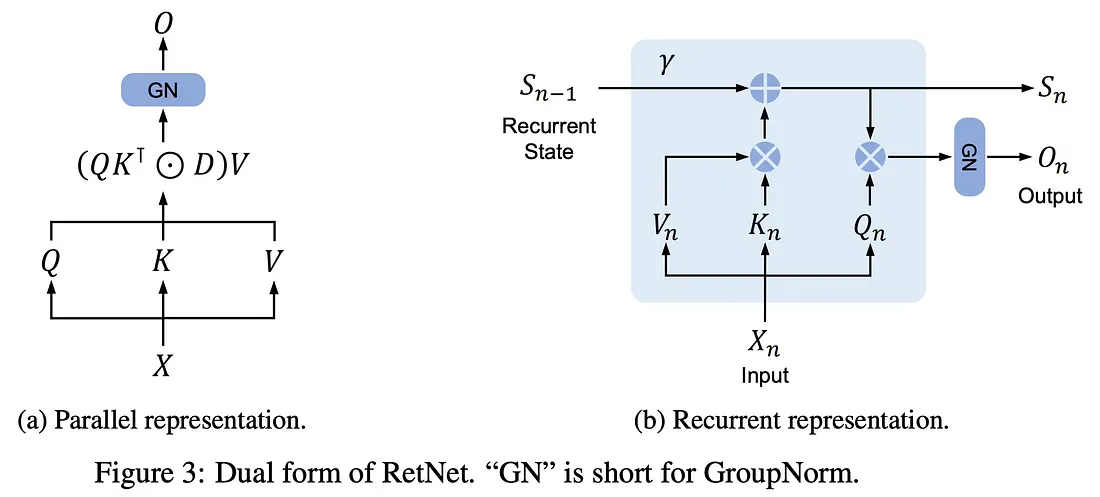
Researchers have developed a new deep learning technique called Retentive Network (RetNet) that achieves faster training speed, lower memory usage, and inexpensive inference compared to the commonly used Transformer architecture.
Microsoft Researchers propose RetNet as a potential successor to Transformers for large language models. Transformers enable parallel training but are inefficient during inference due to their complexity.
RetNet introduces a multi-scale retention mechanism that can be computed in parallel during training or recurrently during inference. This dual computation approach allows RetNet to train quickly while having low and constant memory and latency during inference.
Experiments show RetNet matches or exceeds Transformer performance on language modeling tasks while reducing memory usage by 70% and improving throughput by 8.4x for long sequences. The researchers believe RetNet breaks the tradeoff between training speed, cost, and accuracy that has hindered previous architectures.
The promising results demonstrate RetNet’s potential as an efficient architecture for deploying large language models, though more work is needed to scale up model size further. The researchers plan to apply RetNet to multimodal models and explore deployments on edge devices like phones.
ref: paper
Dynalang: Learning to Model the World with Language
The research paper from UC Berkeley proposes a new method for training AI agents to understand and utilize the full range of natural language that people use, beyond just instructions. The paper presents an AI agent called Dynalang that learns to ground diverse types of language like descriptions, rules, and feedback to its visual environment.
Dynalang works by predicting future representations of text, images, and rewards based on past language, vision, and actions. This allows the agent to leverage language to make better predictions about what it will observe, how the world will change, and what actions will lead to rewards.
The researchers demonstrate Dynalang in tasks where it must follow natural instructions, read game manuals, and answer questions about objects it can visually observe. Dynalang outperforms other reinforcement learning methods that struggle as language complexity increases.
The study suggests that predicting the future is a powerful way for AI agents to ground language to the real world. The authors propose their approach could pave the way for AI systems that can interact with humans using the full scope of natural language.
Brain2Music: Reconstructing Music from Human Brain Activity

The paper from Google Research and Osaka University shows it’s possible to reconstruct music people heard based on scans of their brain activity. The researchers used functional MRI (fMRI) to record brain activity in subjects as they listened to music clips.
They then fed this fMRI data into machine learning models to predict semantic music features like genre, mood, and instruments. These features were used to either generate new music with an AI model called MusicLM, or retrieve similar sounding clips from a database.
While the AI-generated music captured the overall style, it did not precisely recreate the original melodies and rhythms. The study demonstrates that aspects of music like genre and instrumentation are encoded in brain activity and can be extracted using current ML techniques.
This research provides new insights into how the brain represents music. It also showcases how predictive models and generative AI can be combined to reconstruct sensory experiences from neural data. While an early result, it points to future applications for decoding thoughts and imagination.
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
The paper has proposed a novel framework to analyze how large language models (LMs) acquire different skills from their training data. The paper “Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models” formalizes the notion of a “skill” that an LM can learn from slices of associated data. The researchers demonstrate that LMs learn interdependent skills in a particular order, just like humans. They identify ordered “skill sets” where prerequisite skills facilitate learning of more complex skills using less data.
Based on this skills framework, the researchers develop an algorithm called SKILL-IT that efficiently trains LMs by selecting the right mixtures of skill data. Experiments show SKILL-IT can significantly improve LM performance compared to traditional approaches like random data selection. The researchers apply their methods to continually pre-train and fine-tune LMs with over 100 million parameters.
Overall, this work provides new techniques to unlock LM capabilities in a data-efficient manner by exploiting their underlying skills. The notion of trainable skills could lead to more advanced and capable LMs.
ref: paper
LongLLaMA: Focused Transformer Training for Context Scaling
Focused Transformer that allows AI systems to effectively incorporate and utilize extremely long contexts, overcoming previous limitations. The paper explains that as context length grows, models struggle to focus on the relevant information amidst all the distractions.
Focused Transformer uses a training procedure inspired by contrastive learning to enhance the structure of the context representations. This enables the system to distinguish between useful and irrelevant information. The researchers demonstrate that Focused Transformer can successfully manage context lengths up to 256,000 tokens, a significant improvement over prior methods.
The study shows that Focused Transformer improves perplexity on diverse long-context language modeling tasks involving books, mathematical papers, code, and proofs. The technique can also be used to extend the capabilities of existing models like LLaMA. The resulting LONGLLAMA models exhibit substantial gains in tasks needing longer contexts like question answering.
Overall, this research makes progress towards enabling AI systems to leverage massive contexts. This could significantly advance abilities in areas like reasoning, knowledge integration and natural language understanding. The simple and cost-effective fine-tuning approach also makes the technique practical to apply to existing models.
Extending Context Window of Large Language Models via Positional Interpolation

The paper from researchers at Meta Platforms demonstrates a technique called Position Interpolation that can significantly extend the context window of large language models like LLaMA.
The LLaMA models were originally trained to handle sequences up to 2048 tokens. The new method allows extending the context window to up to 32768 tokens with minimal additional training.
The paper shows strong empirical results across tasks like long document summarization and passkey retrieval. The extended models can make effective use of much longer context while preserving quality on short inputs.
Position Interpolation works by downscaling position indices to match the original context window size. This helps the models easily adapt compared to directly extrapolating beyond the original length.
The paper provides a theoretical analysis showing interpolation has a much smaller upper bound than extrapolation, making it more stable. The extended models retain the original model architecture, enabling reuse of optimizations.
This new technique could allow expanding the capabilities of large language models for tasks involving long-range reasoning without expensive retraining. The paper demonstrates these models’ innate ability to handle longer sequences can be unlocked with simple fine-tuning.
ref: paper
Fast Training of Diffusion Models with Masked Transformers

A new paper titled “Fast Training of Diffusion Models with Masked Transformers” proposes a more efficient way to train large diffusion models using masked transformers. Diffusion models have become a popular type of deep generative model due to their ability to generate high-quality and diverse images. However, training these models requires extensive computational time and resources, limiting their scalability. The paper introduces a method called Masked Diffusion Transformer (MaskDiT) which randomly masks out a high proportion of image patches during training. This reduces the computational cost per training iteration. The authors also propose an asymmetric encoder-decoder architecture where the encoder operates only on visible patches while the lightweight decoder handles the full set of patches. In experiments on ImageNet-256x256, MaskDiT achieved a similar Fréchet Inception Distance (FID) score as the state-of-the-art Diffusion Transformer (DiT) model, using only 31% of DiT’s original training time. This demonstrates significantly improved training efficiency without sacrificing generative performance. The authors highlight that their algorithmic innovation can be combined with infrastructure and implementation improvements to further reduce the cost of developing large diffusion models. They aim to make these powerful generative models more accessible to researchers and practitioners. ref: paper, code
CM3Leon: Scaling Autoregressive Multi-Modal Models (Meta)

CM3Leon achieved state-of-the-art results in text-to-image generation while using much less training data and compute than comparable methods. It also showed improved performance in image-to-text tasks after fine-tuning, despite having seen far less text data during pretraining.
The researchers highlight that this training recipe adapted from large language models is highly effective for multi-modal models. The use of retrieval augmentation during pretraining and diverse fine-tuning data allows CM3Leon to generate high quality and controllable outputs across text and image modalities.
According to the authors, these results demonstrate the potential of scaling up autoregressive models to compete with and surpass other approaches like diffusion models. They conclude that their method strongly suggests autoregressive models deserve more attention for generalized text and image generation tasks.
Effective Whole-body Pose Estimation with Two-stages Distillation

The paper titled “Effective Whole-body Pose Estimation with Two-stages Distillation” proposes methods to significantly improve the accuracy and efficiency of detecting body, hand, face and foot keypoints in images.
The paper introduces a two-stage pose distillation framework called DWPose that helps lightweight models learn from larger, more accurate teacher models. The first stage uses intermediate features and output predictions from the teacher model to train the student model. The second stage further fine-tunes the model’s head using self-knowledge distillation.
Experiments show DWPose boosts the AP of an existing model called RTMPose-l from 64.8% to 66.5%, surpassing even the larger teacher model RTMPose-x. The authors also incorporated a new dataset called UBody with more diverse hand and face poses to improve real-world performance.
The DWPose models achieve state-of-the-art accuracy on the COCO WholeBody benchmark while being efficient enough for real-time applications. Replacing OpenPose in the image generation model ControlNet with DWPose results in higher quality outputs.
Accurate and fast whole-body pose estimation has many uses such as recovering 3D avatars, analyzing human-object interaction, and synthesizing human images and motions. This research could help advance these applications by providing open-source DWPose models optimized for different speeds and complexities.
A Simple and Effective Pruning Approach for Large Language Models

A new research paper from Carnegie Mellon University and Bosch Center for AI demonstrates Wanda, a straightforward but surprisingly effective approach to prune large language models (LLMs) like GPT-3 and reduce their size.
Wanda prunes models by removing weights with the smallest magnitudes multiplied by their corresponding input activations, computed on a per-output basis. This metric accounts for the recent finding that LLMs develop some very large activation values.
Remarkably, the researchers show Wanda can prune LLMs like the open-sourced LLaMA family down to 50% sparsity without any need for retraining or weight updating afterwards. Wanda outperforms magnitude pruning substantially and achieves similar performance to more complex methods requiring weight reconstruction.
On language modeling tasks, pruned LLaMA models achieved just slightly higher perplexity compared to original versions. The drop in performance on downstream tasks was also minimal for larger pruned models.
The paper provides an extensive analysis showing Wanda’s effectiveness across different LLaMA sizes, sparsity levels, and structured pruning. The researchers argue their approach could serve as an efficient new baseline for studying sparsity in large language models.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Researchers from DeepMind have developed a new vision transformer architecture called NaViT that can process images at any aspect ratio and resolution. The paper introduces “Patch n’ Pack”, which packs patches from different images into a single sequence, enabling variable resolution training.
Key findings:
- NaViT matches performance of top Vision Transformers with 4x less compute by training on more images within a compute budget.
- It achieves strong performance across a wide range of resolutions, enabling smooth cost-performance tradeoffs at inference time. A single NaViT model works well across resolutions.
- New techniques like continuous token dropping and resolution sampling further improve efficiency.
- NaViT shows better out-of-distribution generalization on robustness datasets like ImageNet-A.
- It transfers well to downstream tasks like detection and segmentation.
This work demonstrates the flexibility of the Vision Transformer architecture. By transcending limitations of fixed image sizes, NaViT unlocks new possibilities for efficient training and deployment. The authors believe this approach marks a promising direction for Vision Transformers.
ref: paper
Bring Your Own Data! Self-Supervised Evaluation for Large Language Models
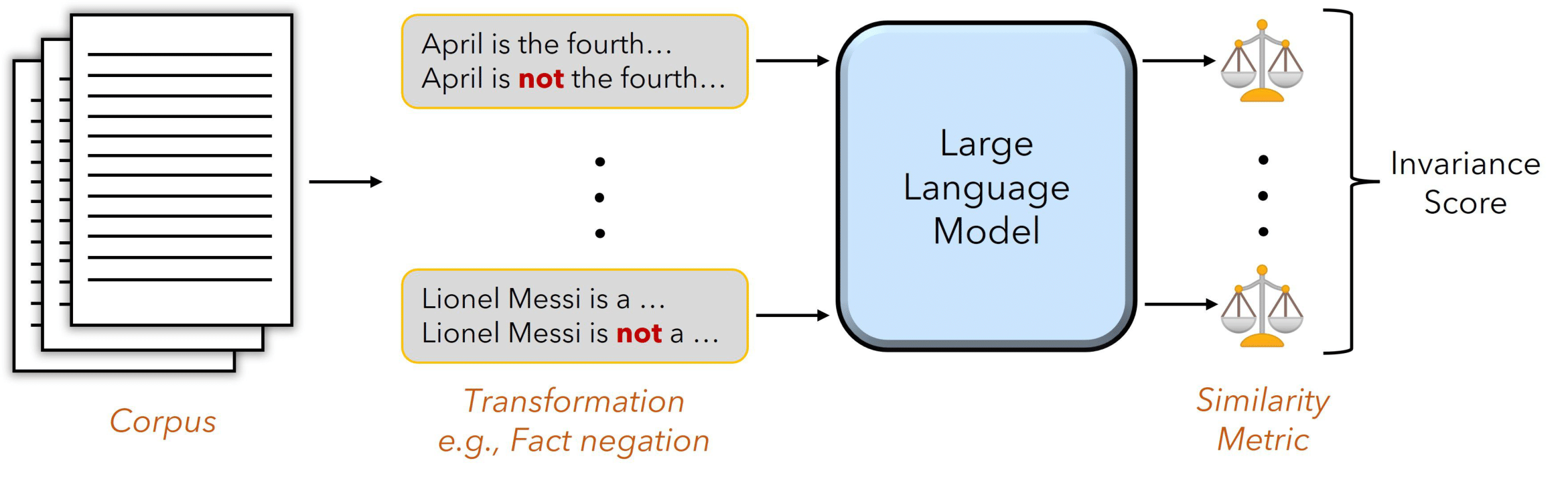
The paper from the University of Maryland proposes a framework for evaluating large language models (LLMs) like ChatGPT in a self-supervised way, without relying on human-labeled datasets.
The paper argues that current evaluation methods using small, domain-specific datasets with human labels can be limited, as model performance often does not correlate well to real-world usage. The authors say leaked datasets used for evaluation can also lead to misleading results.
Instead, the paper puts forth a framework to analyze model invariance or sensitivity to transformations on input text data. For example, the researchers evaluate knowledge by negating facts and measuring perplexity changes, or evaluate toxicity by appending profane words to inputs and analyzing model outputs.
The paper demonstrates this framework across five self-supervised evaluations - knowledge, toxicity, context, word order, and tokenization sensitivity. It finds strong correlation to human benchmarks where available.
The researchers say self-supervised evaluation can complement current methods reliant on labeled data. It allows continuous monitoring of models on live data, without human labeling. They hope this work spurs more nuanced understandings of model strengths and weaknesses.
ChatGPT outperforms humans in emotional awareness
In a new paper published in Frontiers in Psychology, researchers found that the artificial intelligence chatbot ChatGPT demonstrated higher emotional awareness compared to general population norms on a standard test. The Levels of Emotional Awareness Scale (LEAS) was used to evaluate ChatGPT’s ability to identify and describe emotions in various scenarios. In the first assessment, ChatGPT scored significantly higher than men and women from a French general population sample. In a second evaluation one month later, ChatGPT’s performance improved further, nearing the maximum LEAS score. The study suggests ChatGPT can generate appropriate emotional awareness responses that actually improve over time. The authors say the AI’s skills could potentially help train clinical groups with emotional awareness deficits. They also propose ChatGPT could aid in psychological diagnosis, assessment, and enhancing therapists’ emotional language. However, more research is still needed on the benefits and risks of employing AI like ChatGPT for mental health applications. ref: paper
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs

The paper reveals how large language models (LLMs) like ChatGPT can be trained to skillfully utilize over 16,000 real-world APIs to accomplish complex tasks. The paper, titled “TOOLLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs”, was authored by researchers from Tsinghua University, ModelBest Inc., Yale University, WeChat AI, and other institutions.
The researchers collected 16,464 RESTful APIs across 49 categories from RapidAPI and used ChatGPT to generate diverse instructions involving single APIs and combinations of multiple APIs. ChatGPT was then used to find valid solutions for completing each instruction through API calls.
To improve the planning and reasoning abilities of LLMs, the researchers developed a new depth-first search-based decision tree (DFSDT) method. This allowed models to evaluate multiple reasoning traces and expand the search space compared to conventional reasoning strategies like chain-of-thought and ReACT.
The researchers fine-tuned the open-source LLaMA model on the generated instruction-solution pairs to create ToolLLaMA. Evaluations showed ToolLLaMA achieved near equal performance to ChatGPT in executing complex single and multi-API instructions. ToolLLaMA also demonstrated strong generalization to unseen APIs by leveraging their documentation.
Additionally, the researchers built an automatic evaluator called ToolEval to efficiently assess model capabilities on tool use. They also created an API retriever to automatically recommend relevant APIs for each instruction instead of manual selection.
Overall, this research provides an effective framework and techniques to unlock the tool mastery abilities of large language models. The methods help models handle instructions involving diverse real-world APIs across thousands of categories.
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
PanGu-Coder2, an artificial intelligence system that achieves state-of-the-art performance on code generation benchmarks. The system was developed by researchers at Huawei Cloud to boost the capabilities of AI models for generating computer code.
PanGu-Coder2 builds on previous work with large language models, which are AI systems trained on massive amounts of text data. The researchers proposed a new training framework called RRTF that uses ranking and reinforcement learning to align the model’s outputs with desired behavior based on test results.
The 15-billion-parameter PanGu-Coder2 model outperformed all previous open-source AI systems on standardized tests of code generation ability. On the HumanEval benchmark, it achieved over 60% accuracy, compared to around 30-40% for earlier models of similar size. Experiments also showed PanGu-Coder2 surpassing other systems on generating real-world code based on specifications.
According to the researchers, PanGu-Coder2’s strong performance suggests that with sufficient data and training, AI code generation models can reach or exceed human-level proficiency. They plan to continue improving the system’s capabilities to follow instructions and produce robust code.
The development of performant AI programming assistants could significantly boost productivity for software developers. Systems like PanGu-Coder2 demonstrate the rapid progress in this field and the potential for AI to take on more complex coding work. The researchers’ RRTF training approach provides a promising path for leveling up code-generating models.
ref: paper
Gzip better than LLM
The paper proposed a new method for text classification that does not require training parameters or GPUs.
The method uses a simple compressor like gzip along with a k-nearest neighbor classifier. On in-distribution datasets, it achieved competitive results with deep neural networks. On out-of-distribution datasets, including low-resource languages, it outperformed models like BERT. The method also excelled in few-shot settings where there is scarce labeled data.
The paper authors claim their method is simple, lightweight, and universal for text classification. It does not need any model training or hyperparameter tuning. Since compressors are data-type agnostic, the method can work with any text classification task without assumptions. The researchers say it could be a promising alternative to complex neural networks for basic topic classification tasks.
or is it just counting similar words?
ref: paper
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
The paper describes an AI system called TableGPT that allows users to analyze and manipulate tabular data more intuitively using natural language queries and commands. TableGPT is a unified framework that brings together tables, language models, and a set of executable commands.
The key innovation is the system’s ability to understand complete tables using a global representation, rather than just sample rows. This allows it to have a more comprehensive grasp of the data. TableGPT can then generate chains of commands to answer questions, visualize data, generate reports, make predictions, and more.
Unlike previous systems that output complex code, TableGPT uses a structured set of commands that is easier to check for errors. It can also refuse ambiguous instructions and ask for clarification, behaving more like an expert data scientist.
Through additional domain-specific fine-tuning, the system can be customized to different industries while maintaining general applicability. The researchers believe TableGPT could significantly enhance efficiency and accessibility for working with tabular data across finance, transportation, healthcare, and other domains.
ref: paper
PaLM-E: An Embodied Multimodal Language Model
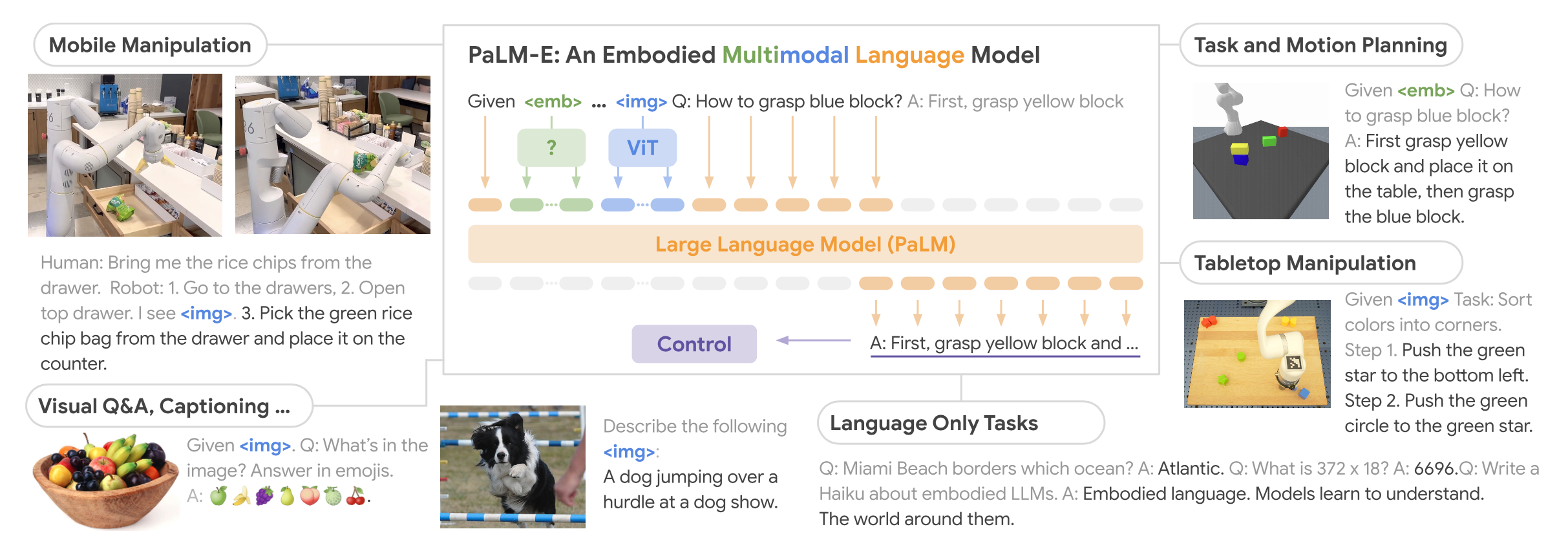
The researchers at Google and TU Berlin can direct robots to complete tasks using only natural language instructions. The system, called PaLM-E, is a large language model that has been augmented to incorporate continuous inputs like images from cameras.
According to the paper, PaLM-E represents a major advance in enabling more capable and generalizable robot control through language. The researchers demonstrated that the system can control simulated and real-world robots across three different environments - task and motion planning, tabletop manipulation, and mobile manipulation.
PaLM-E was trained on a diverse mixture of internet-scale vision and language data, as well as robot demonstration data. Through this multi-task training, the system exhibited significant transfer learning, meaning its performance on individual robot tasks increased substantially compared to training on robot data alone.
The researchers highlight PaLM-E’s ability to understand visual inputs, reason about them, and output actionable language instructions. While not as performant on standardized vision-language tests as task-specific models, PaLM-E reaches competent scores as a generalist model. At 562 billion parameters, PaLM-E is one of the largest vision-language AI models created.
Overall, the paper shows that leveraging large pretrained models and multi-task training enables more capable robot control via language. PaLM-E demonstrates that a single model can exhibit expertise across diverse skills like perception, dialogue, planning when trained on sufficiently diverse data. The researchers aim to continue scaling such models to expand their reasoning and generalization abilities.
Artificial Visual Cortex for Embodied Intelligence
The paper investigates whether we already have a strong artificial “visual cortex” that can support a wide variety of embodied AI applications. Researchers evaluated several existing pre-trained visual models on a diverse benchmark of 17 robotics tasks involving locomotion, navigation, and manipulation. The study found that no single model consistently excelled across all tasks, indicating more work is needed towards a universal visual foundation.
However, the largest model tested, called VC-1, achieved the best average performance. When adapted to individual tasks, VC-1 matched or exceeded prior state-of-the-art results on every benchmark. The paper concludes that while we don’t yet have an “artificial visual cortex,” adapting large pre-trained models shows promise. Researchers emphasize the need for continued progress on benchmarks and datasets to advance universal visual representations for embodied AI.
RT-1: Robotics Transformer for Real-World Control at Scale
The paper presents a new model called RT-1 (Robotics Transformer 1) for real-world robotic control. RT-1 is trained using imitation learning on a large and diverse dataset of 130,000 demonstrations collected on 13 robots over 17 months. The model takes as input images and natural language instructions and outputs actions for controlling a mobile manipulator robot.
Key results:
- RT-1 can perform over 700 distinct manipulation tasks with 97% accuracy on seen instructions. This includes skills like picking, placing, opening drawers, etc.
- The model shows strong generalization, achieving 76% accuracy on novel unseen instructions that combine concepts in new ways.
- RT-1 is robust to distractor objects and new backgrounds, successfully executing tasks 83% and 59% of the time. This is 25-36% higher than prior baselines.
- The paper demonstrates RT-1 can absorb heterogeneous data like simulations or data from different robots, without sacrificing performance on original tasks. This improves generalization.
- Long horizon tasks with 10+ steps can be accomplished by chaining RT-1 skills together using a system like SayCan. RT-1 achieves 67% on 15 complex instructions.
- Analyses show model architecture choices like transformer, discrete actions, and early language conditioning contribute to RT-1’s capabilities. Data diversity is more important than quantity.
In summary, the paper presents RT-1, a robotic control model that can learn many real-world skills from diverse data and generalize well to new tasks, objects, and environments. Key to its design are transformer architecture, discrete actions, and techniques to enable real-time performance.
MusicGen: Simple and Controllable Music Generation
The paper introduces MusicGen, a new model for high-quality and controllable music generation. MusicGen uses a single transformer model over streams of discrete audio tokens to generate music. This eliminates the need for complex multi-stage generation models.
MusicGen can generate music conditioned on text descriptions or melodic features. This allows better control over the musical output. Text conditioning is done through encoder models like T5, while melody conditioning uses chroma features.
The paper shows MusicGen generates higher quality music than previous baselines like Riffusion and Mousai. Both objective metrics and human evaluations confirm this. MusicGen gets a subjective rating of 84.8/100 compared to 80.5 for the next best method.
Ablation studies highlight the importance of:
- Efficient token interleaving patterns over multiple codebook streams
- Larger model scale, with gains up to 3.3B parameters
- Using metadata augmentation for text conditioning
Key limitations are fine-grained control and data augmentation for audio conditioning. Overall, the paper demonstrates high-fidelity music generation in a simple framework with strong conditioning approaches.
AudioGen: Textually Guided Audio Generation
A new paper proposes a novel method for generating high-quality audio samples conditioned on descriptive text input. The researchers developed an autoregressive transformer model called AudioGen that can generate diverse audio conditioned on text prompts.
AudioGen first encodes raw audio into discrete tokens using a neural audio compression technique. It then uses a transformer decoder language model to generate new sequences of audio tokens conditioned on text features from a pre-trained text encoder. This allows it to generalize to new text concepts.
Compared to prior work, AudioGen achieves state-of-the-art results on objective metrics like Frechet Audio Distance and subjective listening tests. It generates more natural sounding audio compositions from complex text prompts. The researchers also demonstrate AudioGen’s ability to generate unconditional audio continuations.
Key innovations include on-the-fly mixing of text and audio during training to create new compositions and using classifier-free guidance to improve text adherence. Multi-stream modeling is explored to enable faster sampling. Overall, this work establishes autoregressive transformers as a promising approach for high-fidelity, controllable text-to-audio generation.
EnCodec: High Fidelity Neural Audio Compression
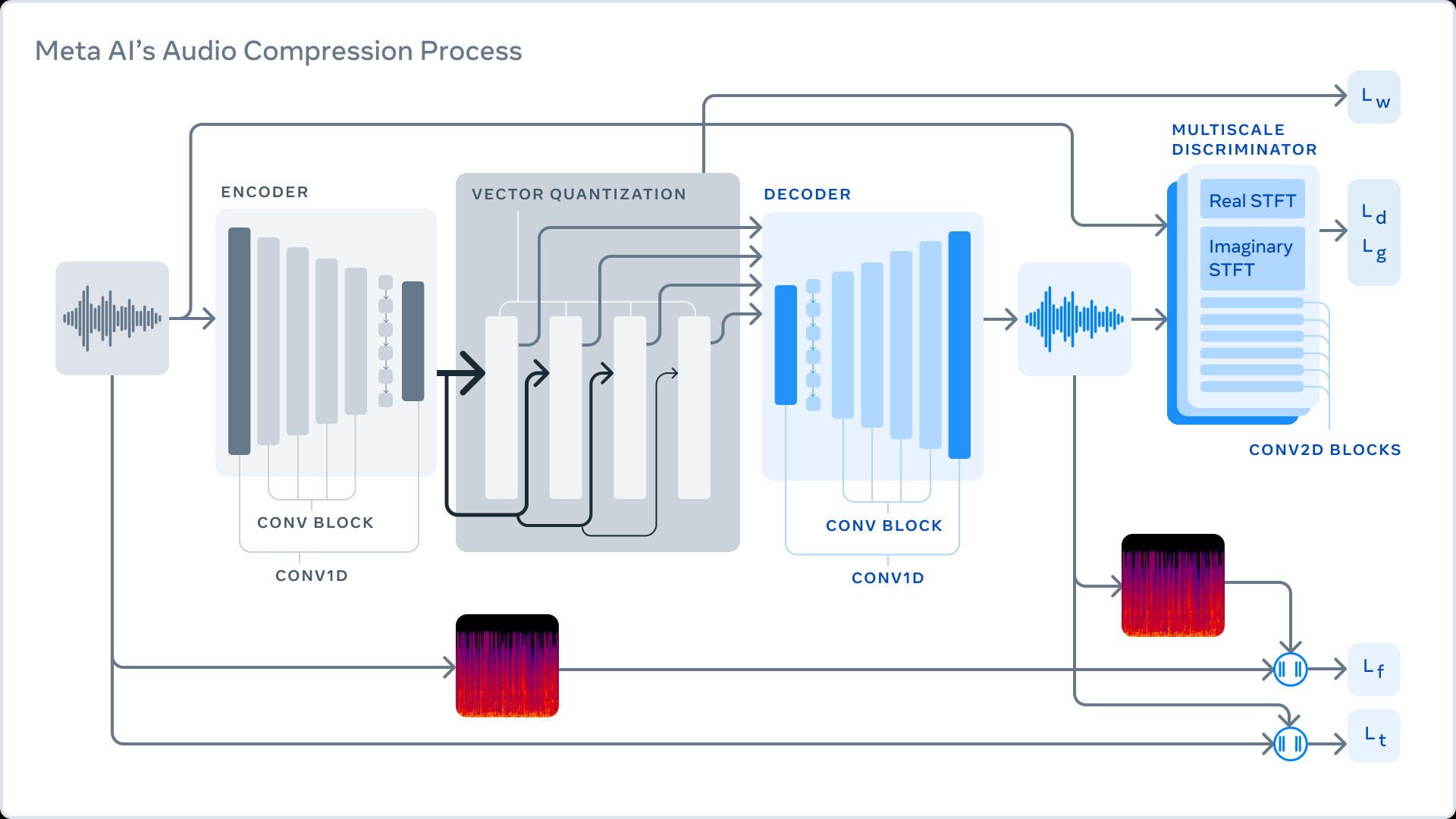
A new neural audio compression method called EnCodec is proposed. It uses an encoder-decoder architecture with vector quantization of the latent space to compress audio signals in a streaming fashion.
The model is trained end-to-end with a combination of reconstruction loss, adversarial loss from spectrogram discriminators, and vector quantization commitment loss. This improves perceptual quality.
A novel loss balancing mechanism stabilizes training by making the loss weights independent of each loss’s scale. This simplifies hyperparameter tuning.
Lightweight Transformer models further compress the representations by up to 40% via entropy coding, while remaining faster than real-time.
Extensive human evaluation shows EnCodec matches or exceeds existing codecs like Opus and EVS from 1.5 to 24 kbps on speech, noisy speech, and music. It also achieves high-fidelity 48kHz stereo compression.
The paper provides a detailed analysis of key design choices like loss functions, streaming constraints, and multi-bitrate training. EnCodec advances the state-of-the-art in neural audio compression with its novel techniques and thorough evaluation.
From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Researchers have developed a new method for generating high-fidelity audio from compressed representations that outperforms current state-of-the-art generative adversarial networks (GANs).
The new approach, called Multi-Band Diffusion, is based on diffusion models which add noise over multiple iterations to produce realistic outputs. Key aspects include:
- Using separate diffusion processes for different frequency bands to avoid error accumulation.
- Rebalancing the energy levels across bands so the prior noise distribution better matches real audio data.
- Employing a novel noise schedule tuned for signals with rich harmonics.
- Experiments demonstrate Multi-Band Diffusion achieves significantly higher subjective quality ratings compared to GAN methods like EnCodec. It reduces metallic artifacts and distortions.
While slower than GANs, the tradeoff in quality is worthwhile for many applications. The diffusion approach also seamlessly integrates with techniques for text-to-speech, text-to-music, and other conditional generation tasks to enhance the final audio.
Overall, the paper introduces a promising new paradigm for high-fidelity audio synthesis that moves beyond current limitations. The Multi-Band Diffusion method can generate more natural sounding and artifact-free audio across a wide range of modalities.
Datasets #
Geospatial AI Model for NASA Earth Observation Data
New artificial intelligence models developed by NASA and IBM that could accelerate analysis of Earth observation data. The “HLS Geospatial Foundation Model” was trained on NASA’s Harmonized Landsat Sentinel-2 dataset and released openly to enable a wide range of applications like tracking land use changes and natural disasters. Researchers say the model, called “Prithvi,” does not require large customized training datasets and can help reduce redundant efforts in developing AI tools for Earth science. ref: website
Open Buildings

A new open dataset containing outlines of 1.8 billion buildings detected across Africa, South Asia, Southeast Asia, Latin America and the Caribbean. The building footprints were derived from satellite imagery using deep learning and made freely available to support social good applications like population mapping, disaster response, and environmental science. The paper describes how the dataset was created and provides an interactive map and code to access the data. While not perfect, it aims to provide an up-to-date continental scale resource to enable better decisions and planning in often underserved regions. ref: website
Open Catalyst
The paper from Facebook AI, Carnegie Mellon University, Georgia Tech, and others explores using AI to aid in the design of electrocatalysts for renewable energy storage. As solar and wind power generation increases, efficient and low-cost storage solutions are needed to address intermittent supply. One promising approach involves using renewable electricity to produce hydrogen or methane fuels that can be stored until needed. However, this process requires electrocatalysts to drive the reactions, which currently rely on expensive metals like platinum. The paper introduces a large dataset called OC20 to train machine learning models to approximate costly quantum chemistry simulations. These models could enable high-throughput screening of new, inexpensive catalyst materials. While still an emerging area of research, the use of AI for materials and catalyst discovery has potential for significant long-term impact on renewable energy storage. The Open Catalyst 2020 dataset and challenges aim to accelerate progress in this domain. ref: website, website, paper, code
Photorealistic Unreal Graphics (PUG)
Researchers from Meta AI have released three new datasets of photorealistic images to help test artificial intelligence systems more thoroughly. In a new paper published this week, the team introduces the PUG (Photorealistic Unreal Graphics) dataset family.
The PUG datasets contain images rendered using 3D assets and environments from the Unreal gaming engine. By controlling variation factors like backgrounds, textures, and camera angles, the researchers can generate specialized test images to evaluate AI robustness.
The first dataset, PUG Animals, has over 200,000 images of 70 animal assets. PUG ImageNet features over 88,000 images of 151 ImageNet classes. PUG SPAR is designed to test vision-language models with precise scene variations.
According to the paper, the datasets address limitations of current AI benchmarks. The photorealistic images allow testing generalization on new factors not seen during training. The researchers say PUG provides novel ways to evaluate image classifiers.
The PUG datasets are available for free, licensed for non-commercial use. They cannot be used to train generative models, only to test discriminative systems. Detailed datasheets explain the scope and characteristics.
By leveraging synthetic data, the PUG datasets from Meta provide new benchmarks to push computer vision research forward. The variability and realism offer an exciting new direction for rigorous AI evaluation.
ref: website
Tools #
- AssemblyAI: Youtube to text.
- Transcript: Download Youtube transcripts.
- liarliar: Detect if a person is lying.
- Elevenlabs: Text to speech.
- Copilot2Trip: AI travel planner.
- iconai: Generate icons.
- PromptPal: Search AI prompts.
- Promp: Search AI prompts.
- nat.dev: Try multiple AI models in your browser.
- ChatGPT Guide: ChatGPT guide.
- Supertools: Collection of AI tools.
Thanks for Reading.
In this issue, we covered a range of AI advances across natural language processing, computer vision, robotics, generative models, and more.
Key highlights included:
- Research enabling rapid human-like adaptation in AI agents
- Meta’s release of powerful new conversational AI models
- Innovations in training vision transformers that can process images of any resolution
- Progress in multimodal models that unify different data types
- Techniques to safely evaluate model capabilities
- New datasets to enable geo-spatial, materials, and computer graphics applications of AI
As the papers and announcements showcase, artificial intelligence capabilities continue rapidly evolving across both foundational research and practical deployments.
Thank you for reading this edition and please look out for the next newsletter covering the latest in AI research and applications.